 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeID and OOD Performance Are Sometimes Inversely Correlated on Real-world Datasets
Paper and Code
Sep 01, 2022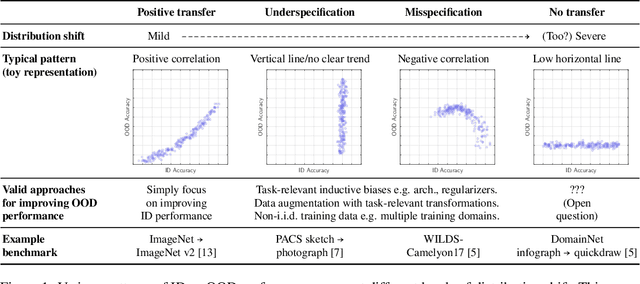
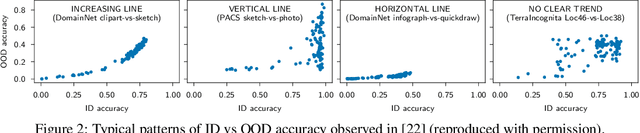
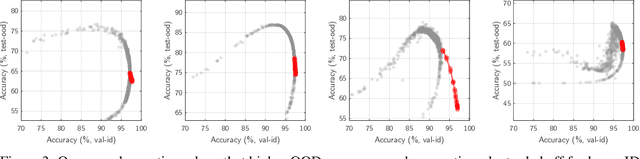
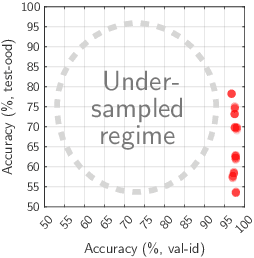
Several studies have empirically compared in-distribution (ID) and out-of-distribution (OOD) performance of various models. They report frequent positive correlations on benchmarks in computer vision and NLP. Surprisingly, they never observe inverse correlations suggesting necessary trade-offs. This matters to determine whether ID performance can serve as a proxy for OOD generalization. This short paper shows that inverse correlations between ID and OOD performance do happen in real-world benchmarks. They may have been missed in past studies because of a biased selection of models. We show an example of the pattern on the WILDS-Camelyon17 dataset, using models from multiple training epochs and random seeds. Our observations are particularly striking on models trained with a regularizer that diversifies the solutions to the ERM objective. We nuance recommendations and conclusions made in past studies. (1) High OOD performance does sometimes require trading off ID performance. (2) Focusing on ID performance alone may not lead to optimal OOD performance: it can lead to diminishing and eventually negative returns in OOD performance. (3) Our example reminds that empirical studies only chart regimes achievable with existing methods: care is warranted in deriving prescriptive recommendations.