 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAFARI: Versatile and Efficient Evaluations for Robustness of Interpretability
Paper and Code
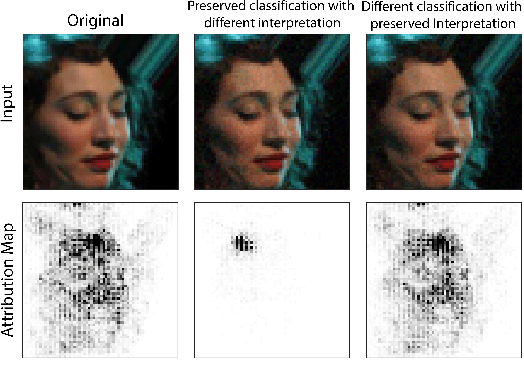
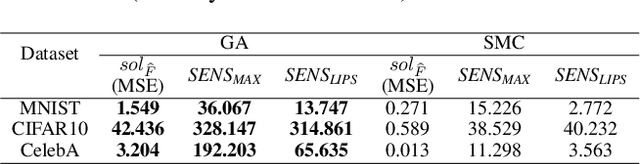
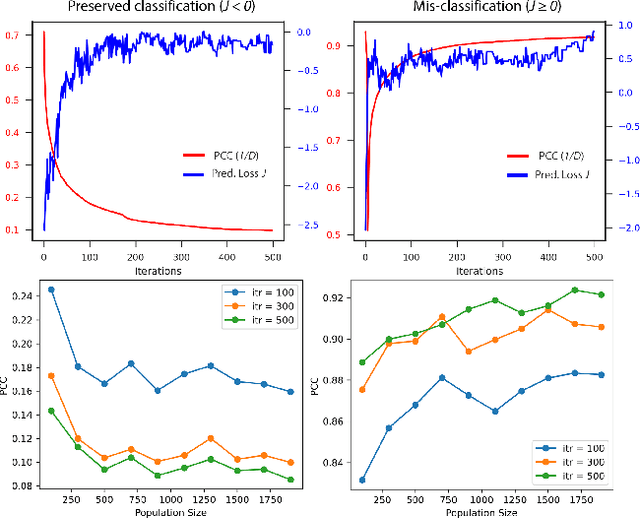
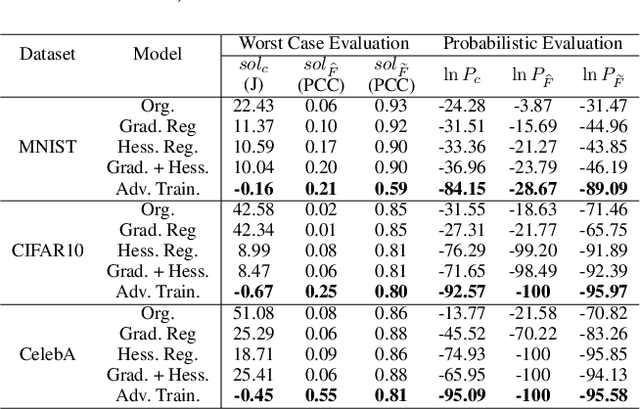
Interpretability of Deep Learning (DL) models is arguably the barrier in front of trustworthy AI. Despite great efforts made by the Explainable AI (XAI) community, explanations lack robustness--indistinguishable input perturbations may lead to different XAI results. Thus, it is vital to assess how robust DL interpretability is, given an XAI technique. To this end, we identify the following challenges that state-of-the-art is unable to cope with collectively: i) XAI techniques are highly heterogeneous; ii) misinterpretations are normally rare events; iii) both worst-case and overall robustness are of practical interest. In this paper, we propose two evaluation methods to tackle them--i) they are of black-box nature, based on Genetic Algorithm (GA) and Subset Simulation (SS); ii) bespoke fitness functions are used by GA to solve a constrained optimisation efficiently, while SS is dedicated to estimating rare event probabilities; iii) two diverse metrics are introduced, concerning the worst-case interpretation discrepancy and a probabilistic notion of \textit{how} robust in general, respectively. We conduct experiments to study the accuracy, sensitivity and efficiency of our methods that outperform state-of-the-arts. Finally, we show two applications of our methods for ranking robust XAI methods and selecting training schemes to improve both classification and interpretation robustness.