 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistinctive Image Captioning via CLIP Guided Group Optimization
Paper and Code
Aug 14, 2022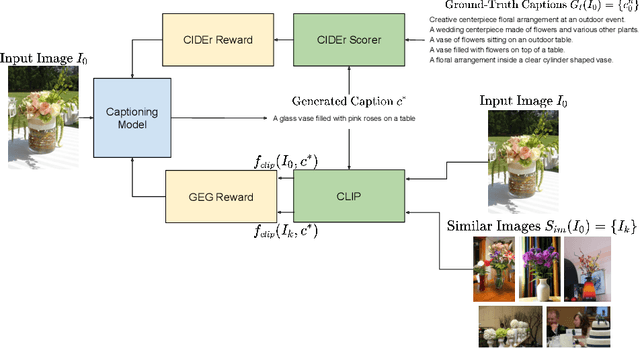
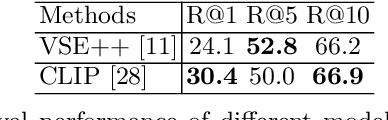
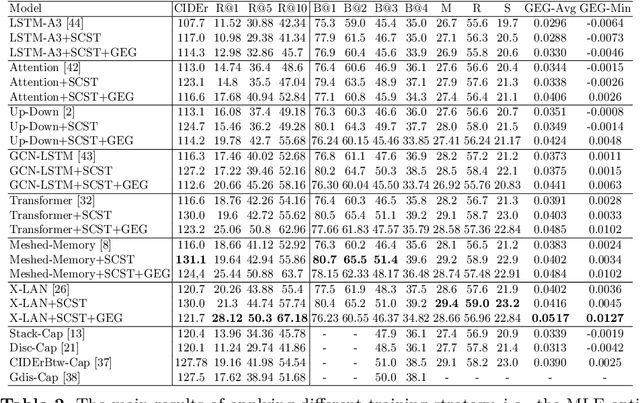
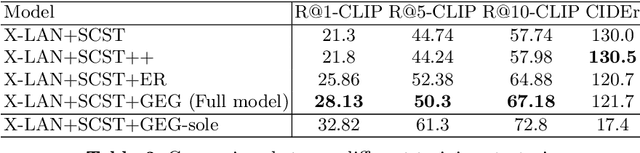
Image captioning models are usually trained according to human annotated ground-truth captions, which could generate accurate but generic captions. In this paper, we focus on generating the distinctive captions that can distinguish the target image from other similar images. To evaluate the distinctiveness of captions, we introduce a series of metrics that use large-scale vision-language pre-training model CLIP to quantify the distinctiveness. To further improve the distinctiveness of captioning models, we propose a simple and effective training strategy which trains the model by comparing target image with similar image group and optimizing the group embedding gap. Extensive experiments are conducted on various baseline models to demonstrate the wide applicability of our strategy and the consistency of metric results with human evaluation. By comparing the performance of our best model with existing state-of-the-art models, we claim that our model achieves new state-of-the-art towards distinctiveness objective.