 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Memory Efficient Training via Dual Activation Precision
Paper and Code
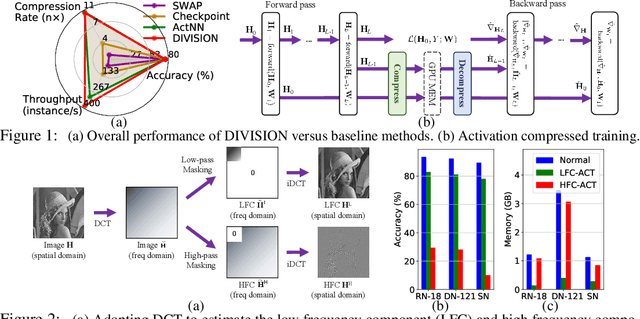
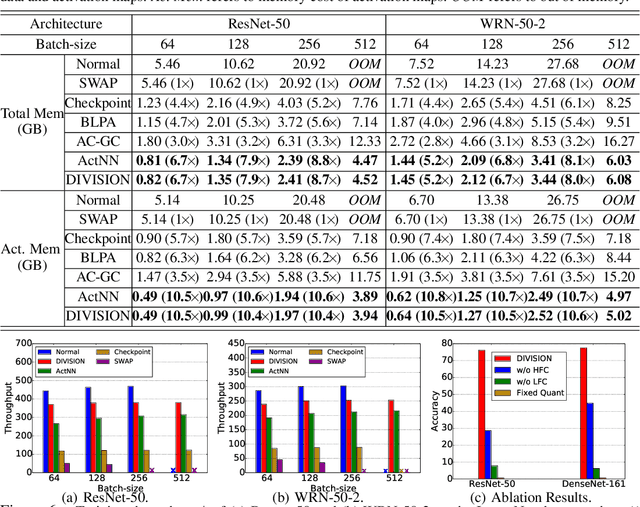
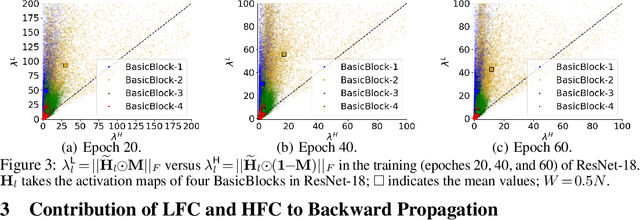
Activation compressed training~(ACT) has been shown to be a promising way to reduce the memory consumption in training deep neural networks. However, existing work of ACT relies on searching for the optimal bit-width during deep neural network (DNN) training to reduce the quantization noise, which makes the procedure complicated and less transparent. To this end, we propose a simple and effective ACT method for DNN training. Our method is motivated by the observation: \emph{DNN backward propagation mainly depends on the low-frequency component~(LFC) of the activation maps instead of the high-frequency component~(HFC)}. It indicates the HFC of the activation maps is highly redundant and compressible during DNN training, which inspires our proposed Dual ActIVation PrecISION~(DIVISION). During the training, DIVISION estimates both the LFC and HFC of the activation maps, and compresses the HFC into low-precision copy to remove the redundancy. This can significantly reduce the memory consumption without negatively affecting the precision of DNN backward propagation. In this way, DIVISION achieves comparable performance as normal training. Experimental results on three benchmark datasets demonstrate that DIVISION outperforms state-of-the-art baseline methods in terms of memory consumption, model accuracy, and running speed.