 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised learning with rotation-invariant kernels
Paper and Code
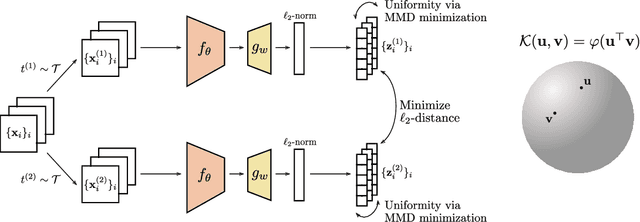
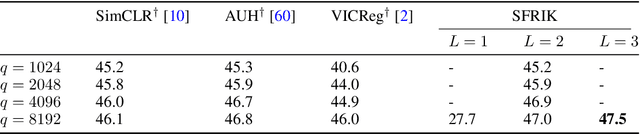
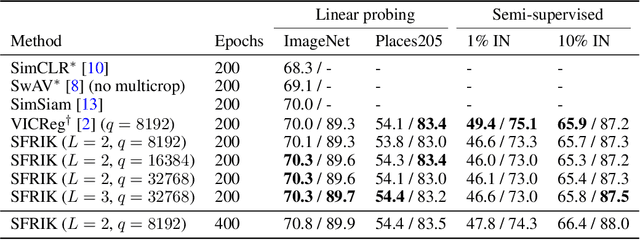

A major paradigm for learning image representations in a self-supervised manner is to learn a model that is invariant to some predefined image transformations (cropping, blurring, color jittering, etc.), while regularizing the embedding distribution to avoid learning a degenerate solution. Our first contribution is to propose a general kernel framework to design a generic regularization loss that promotes the embedding distribution to be close to the uniform distribution on the hypersphere, with respect to the maximum mean discrepancy pseudometric. Our framework uses rotation-invariant kernels defined on the hypersphere, also known as dot-product kernels. Our second contribution is to show that this flexible kernel approach encompasses several existing self-supervised learning methods, including uniformity-based and information-maximization methods. Finally, by exploring empirically several kernel choices, our experiments demonstrate that using a truncated rotation-invariant kernel provides competitive results compared to state-of-the-art methods, and we show practical situations where our method benefits from the kernel trick to reduce computational complexity.