 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Feature Alignment Network for Unsupervised Video Object Segmentation
Paper and Code
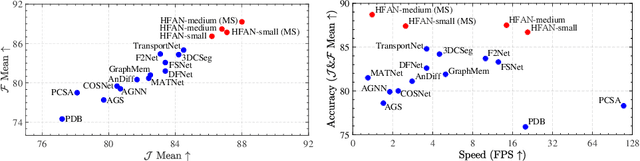

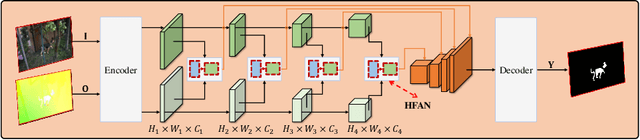
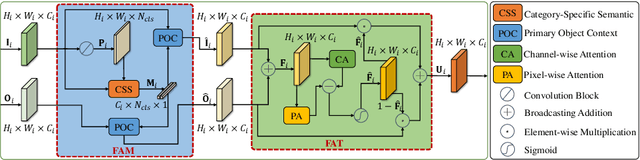
Optical flow is an easily conceived and precious cue for advancing unsupervised video object segmentation (UVOS). Most of the previous methods directly extract and fuse the motion and appearance features for segmenting target objects in the UVOS setting. However, optical flow is intrinsically an instantaneous velocity of all pixels among consecutive frames, thus making the motion features not aligned well with the primary objects among the corresponding frames. To solve the above challenge, we propose a concise, practical, and efficient architecture for appearance and motion feature alignment, dubbed hierarchical feature alignment network (HFAN). Specifically, the key merits in HFAN are the sequential Feature AlignMent (FAM) module and the Feature AdaptaTion (FAT) module, which are leveraged for processing the appearance and motion features hierarchically. FAM is capable of aligning both appearance and motion features with the primary object semantic representations, respectively. Further, FAT is explicitly designed for the adaptive fusion of appearance and motion features to achieve a desirable trade-off between cross-modal features. Extensive experiments demonstrate the effectiveness of the proposed HFAN, which reaches a new state-of-the-art performance on DAVIS-16, achieving 88.7 $\mathcal{J}\&\mathcal{F}$ Mean, i.e., a relative improvement of 3.5% over the best published result.