 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Age Speaker Verification: Learning Age-Invariant Speaker Embeddings
Paper and Code
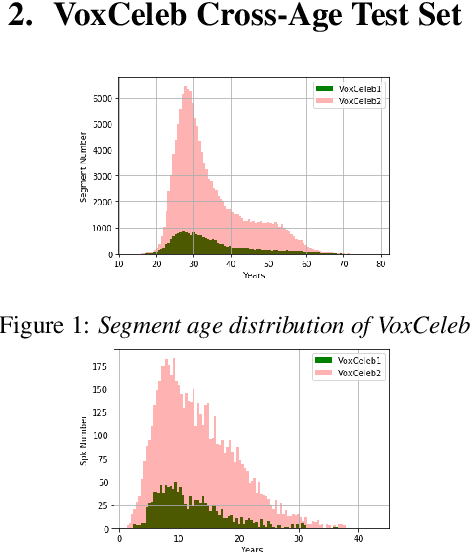
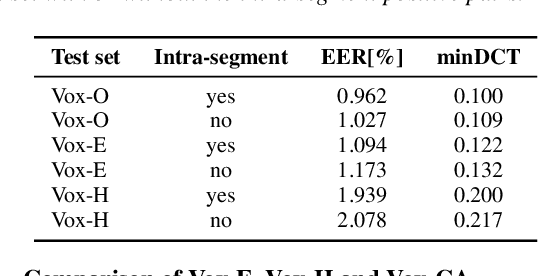
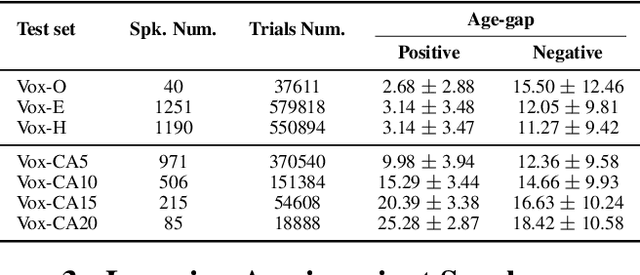
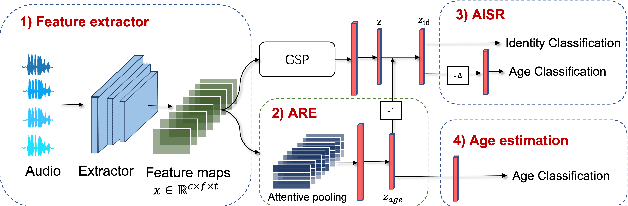
Automatic speaker verification has achieved remarkable progress in recent years. However, there is little research on cross-age speaker verification (CASV) due to insufficient relevant data. In this paper, we mine cross-age test sets based on the VoxCeleb dataset and propose our age-invariant speaker representation(AISR) learning method. Since the VoxCeleb is collected from the YouTube platform, the dataset consists of cross-age data inherently. However, the meta-data does not contain the speaker age label. Therefore, we adopt the face age estimation method to predict the speaker age value from the associated visual data, then label the audio recording with the estimated age. We construct multiple Cross-Age test sets on VoxCeleb (Vox-CA), which deliberately select the positive trials with large age-gap. Also, the effect of nationality and gender is considered in selecting negative pairs to align with Vox-H cases. The baseline system performance drops from 1.939\% EER on the Vox-H test set to 10.419\% on the Vox-CA20 test set, which indicates how difficult the cross-age scenario is. Consequently, we propose an age-decoupling adversarial learning (ADAL) method to alleviate the negative effect of the age gap and reduce intra-class variance. Our method outperforms the baseline system by over 10\% related EER reduction on the Vox-CA20 test set. The source code and trial resources are available on https://github.com/qinxiaoyi/Cross-Age_Speaker_Verification