 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Role Aware Correlation Transformer for Text to Video Retrieval
Paper and Code
Jun 26, 2022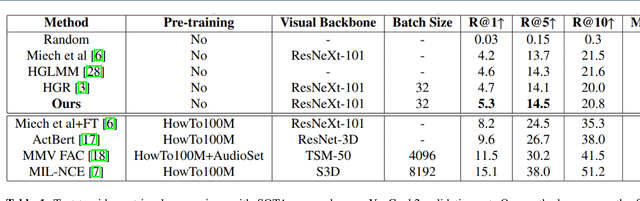

With the emergence of social media, voluminous video clips are uploaded every day, and retrieving the most relevant visual content with a language query becomes critical. Most approaches aim to learn a joint embedding space for plain textual and visual contents without adequately exploiting their intra-modality structures and inter-modality correlations. This paper proposes a novel transformer that explicitly disentangles the text and video into semantic roles of objects, spatial contexts and temporal contexts with an attention scheme to learn the intra- and inter-role correlations among the three roles to discover discriminative features for matching at different levels. The preliminary results on popular YouCook2 indicate that our approach surpasses a current state-of-the-art method, with a high margin in all metrics. It also overpasses two SOTA methods in terms of two metrics.