 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEStereo-Du2CNN: A Novel Dual Channel CNN for Learning Robust Depth Estimates from Multi-exposure Stereo Images for HDR 3D Applications
Paper and Code
Jun 21, 2022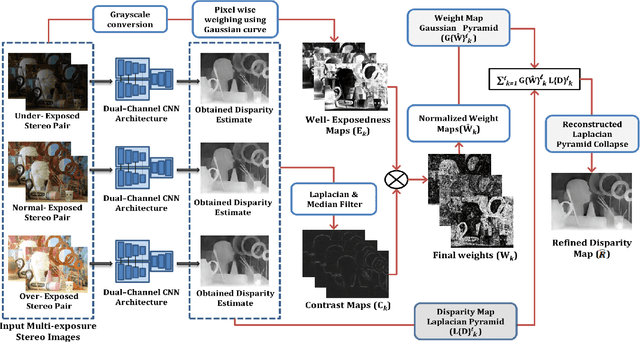
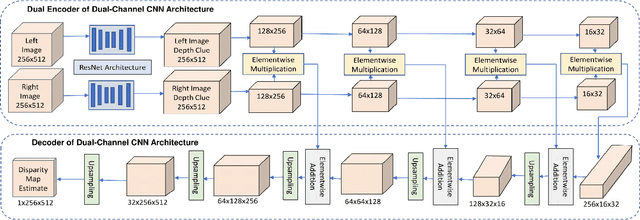
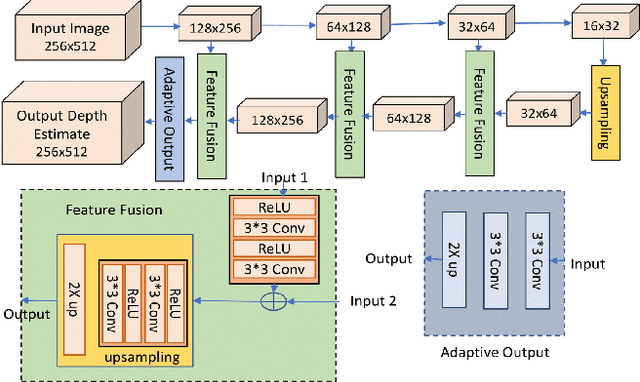

Display technologies have evolved over the years. It is critical to develop practical HDR capturing, processing, and display solutions to bring 3D technologies to the next level. Depth estimation of multi-exposure stereo image sequences is an essential task in the development of cost-effective 3D HDR video content. In this paper, we develop a novel deep architecture for multi-exposure stereo depth estimation. The proposed architecture has two novel components. First, the stereo matching technique used in traditional stereo depth estimation is revamped. For the stereo depth estimation component of our architecture, a mono-to-stereo transfer learning approach is deployed. The proposed formulation circumvents the cost volume construction requirement, which is replaced by a ResNet based dual-encoder single-decoder CNN with different weights for feature fusion. EfficientNet based blocks are used to learn the disparity. Secondly, we combine disparity maps obtained from the stereo images at different exposure levels using a robust disparity feature fusion approach. The disparity maps obtained at different exposures are merged using weight maps calculated for different quality measures. The final predicted disparity map obtained is more robust and retains best features that preserve the depth discontinuities. The proposed CNN offers flexibility to train using standard dynamic range stereo data or with multi-exposure low dynamic range stereo sequences. In terms of performance, the proposed model surpasses state-of-the-art monocular and stereo depth estimation methods, both quantitatively and qualitatively, on challenging Scene flow and differently exposed Middlebury stereo datasets. The architecture performs exceedingly well on complex natural scenes, demonstrating its usefulness for diverse 3D HDR applications.