 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeByteComp: Revisiting Gradient Compression in Distributed Training
Paper and Code
Jun 06, 2022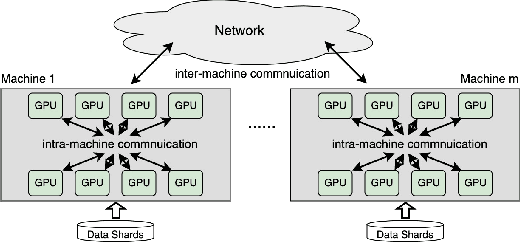
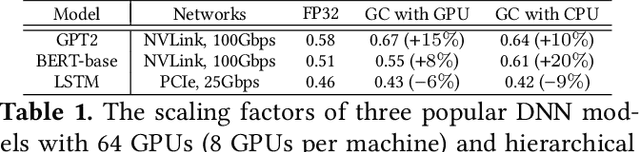


Gradient compression (GC) is a promising approach to addressing the communication bottleneck in distributed deep learning (DDL). However, it is challenging to find the optimal compression strategy for applying GC to DDL because of the intricate interactions among tensors. To fully unleash the benefits of GC, two questions must be addressed: 1) How to express all compression strategies and the corresponding interactions among tensors of any DDL training job? 2) How to quickly select a near-optimal compression strategy? In this paper, we propose ByteComp to answer these questions. It first designs a decision tree abstraction to express all the compression strategies and develops empirical models to timeline tensor computation, communication, and compression to enable ByteComp to derive the intricate interactions among tensors. It then designs a compression decision algorithm that analyzes tensor interactions to eliminate and prioritize strategies and optimally offloads compression to CPUs. Experimental evaluations show that ByteComp can improve the training throughput over the start-of-the-art compression-enabled system by up to 77% for representative DDL training jobs. Moreover, the computational time needed to select the compression strategy is measured in milliseconds, and the selected strategy is only a few percent from optimal.