 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatching Leaks in the Charformer for Efficient Character-Level Generation
Paper and Code
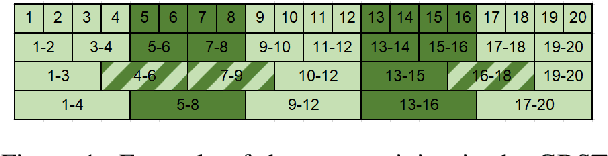

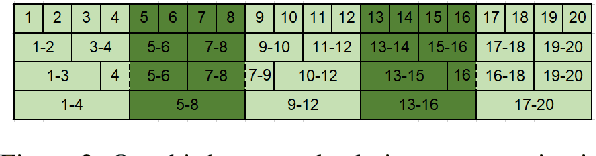
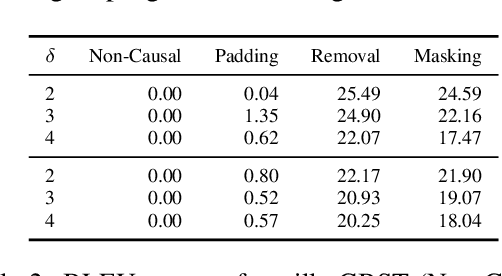
Character-based representations have important advantages over subword-based ones for morphologically rich languages. They come with increased robustness to noisy input and do not need a separate tokenization step. However, they also have a crucial disadvantage: they notably increase the length of text sequences. The GBST method from Charformer groups (aka downsamples) characters to solve this, but allows information to leak when applied to a Transformer decoder. We solve this information leak issue, thereby enabling character grouping in the decoder. We show that Charformer downsampling has no apparent benefits in NMT over previous downsampling methods in terms of translation quality, however it can be trained roughly 30% faster. Promising performance on English--Turkish translation indicate the potential of character-level models for morphologically-rich languages.