 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast variable selection makes scalable Gaussian process BSS-ANOVA a speedy and accurate choice for tabular and time series regression
Paper and Code
May 26, 2022
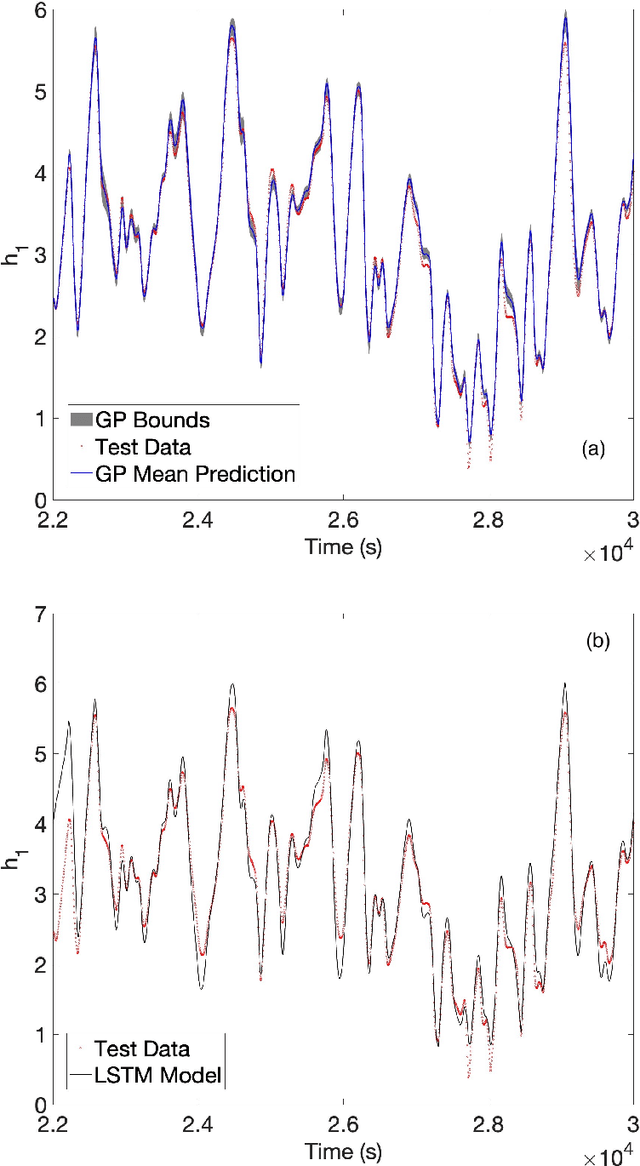

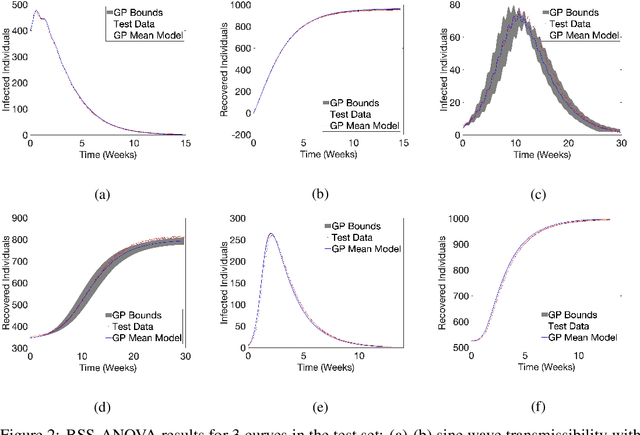
Gaussian processes (GPs) are non-parametric regression engines with a long history. They are often overlooked in modern machine learning contexts because of scalability issues: regression for traditional GP kernels are $\mathcal{O}(N^3)$ where $N$ is the size of the dataset. One of a number of scalable GP approaches is the Karhunen-Lo\'eve (KL) decomposed kernel BSS-ANOVA, developed in 2009. It is $\mathcal{O}(NP)$ in training and $\mathcal{O}(P)$ per point in prediction, where $P$ is the number of terms in the ANOVA / KL expansion. A new method of forward variable selection, quickly and effectively limits the number of terms, yielding a method with competitive accuracies, training and inference times for large tabular datasets. The new algorithm balances model fidelity with model complexity using Bayesian and Akaike information criteria (BIC/AIC). The inference speed and accuracy makes the method especially useful for modeling dynamic systems in a model-free manner, by modeling the derivative in a dynamic system as a static problem, then integrating the learned dynamics using a high-order scheme. The methods are demonstrated on a `Susceptible, Infected, Recovered' (SIR) toy problem, with the transmissibility used as forcing function, along with the `Cascaded Tanks' benchmark dataset. Comparisons on the static prediction of derivatives are made with a Random Forest and Residual Neural Network, while for the timeseries prediction comparisons are made with LSTM and GRU recurrent neural networks. The GP outperforms the other methods in all modeling tasks on accuracy, while (in the case of the neural networks) performing many orders of magnitude fewer calculations. For the SIR test, which involved prediction for a set of forcing functions qualitatively different from those appearing in the training set, the GP captured the correct dynamics while the neural networks failed to do so.