 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Policies with DOMiNO: Diversity Optimization Maintaining Near Optimality
Paper and Code
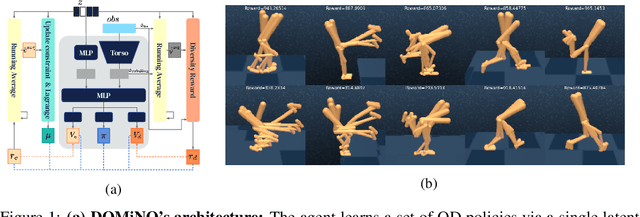
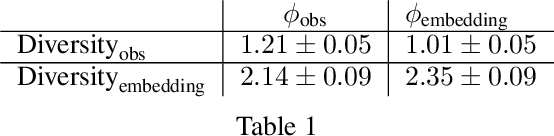
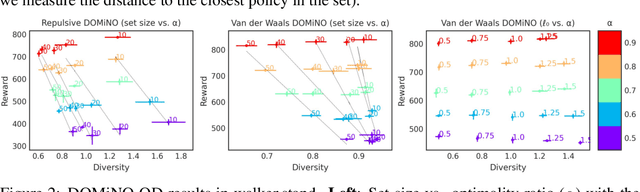
Finding different solutions to the same problem is a key aspect of intelligence associated with creativity and adaptation to novel situations. In reinforcement learning, a set of diverse policies can be useful for exploration, transfer, hierarchy, and robustness. We propose DOMiNO, a method for Diversity Optimization Maintaining Near Optimality. We formalize the problem as a Constrained Markov Decision Process where the objective is to find diverse policies, measured by the distance between the state occupancies of the policies in the set, while remaining near-optimal with respect to the extrinsic reward. We demonstrate that the method can discover diverse and meaningful behaviors in various domains, such as different locomotion patterns in the DeepMind Control Suite. We perform extensive analysis of our approach, compare it with other multi-objective baselines, demonstrate that we can control both the quality and the diversity of the set via interpretable hyperparameters, and show that the discovered set is robust to perturbations.