Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy only Micro-F1? Class Weighting of Measures for Relation Classification
Paper and Code


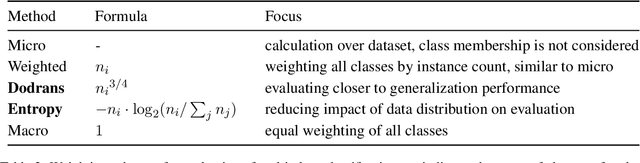
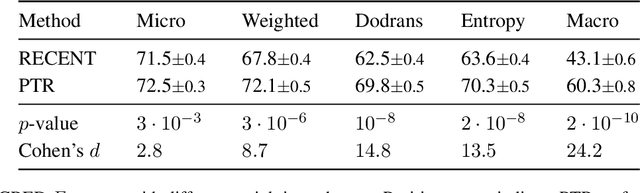
Relation classification models are conventionally evaluated using only a single measure, e.g., micro-F1, macro-F1 or AUC. In this work, we analyze weighting schemes, such as micro and macro, for imbalanced datasets. We introduce a framework for weighting schemes, where existing schemes are extremes, and two new intermediate schemes. We show that reporting results of different weighting schemes better highlights strengths and weaknesses of a model.
* NLP Power! The First Workshop on Efficient Benchmarking in NLP (ACL
2022)
View paper on