 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Textual Adversarial Examples Based on Distributional Characteristics of Data Representations
Paper and Code


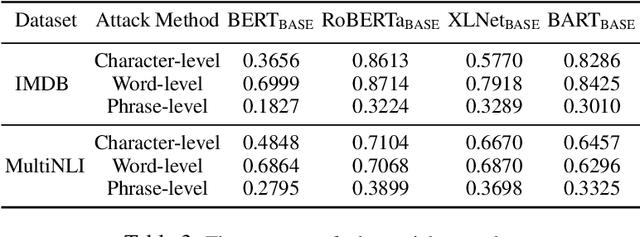

Although deep neural networks have achieved state-of-the-art performance in various machine learning tasks, adversarial examples, constructed by adding small non-random perturbations to correctly classified inputs, successfully fool highly expressive deep classifiers into incorrect predictions. Approaches to adversarial attacks in natural language tasks have boomed in the last five years using character-level, word-level, phrase-level, or sentence-level textual perturbations. While there is some work in NLP on defending against such attacks through proactive methods, like adversarial training, there is to our knowledge no effective general reactive approaches to defence via detection of textual adversarial examples such as is found in the image processing literature. In this paper, we propose two new reactive methods for NLP to fill this gap, which unlike the few limited application baselines from NLP are based entirely on distribution characteristics of learned representations: we adapt one from the image processing literature (Local Intrinsic Dimensionality (LID)), and propose a novel one (MultiDistance Representation Ensemble Method (MDRE)). Adapted LID and MDRE obtain state-of-the-art results on character-level, word-level, and phrase-level attacks on the IMDB dataset as well as on the later two with respect to the MultiNLI dataset. For future research, we publish our code.