 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Text Formality: A Study of Text Classification Approaches
Paper and Code

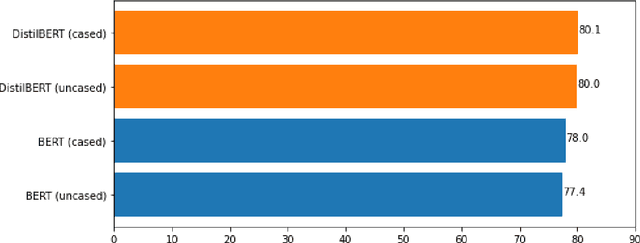
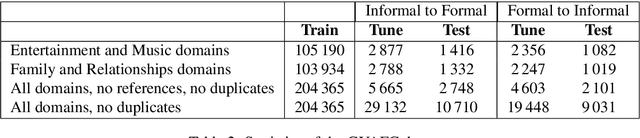
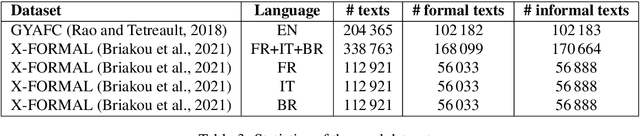
Formality is an important characteristic of text documents. The automatic detection of the formality level of a text is potentially beneficial for various natural language processing tasks, such as retrieval of texts with a desired formality level, integration in language learning and document editing platforms, or evaluating the desired conversation tone by chatbots. Recently two large-scale datasets were introduced for multiple languages featuring formality annotation. However, they were primarily used for the training of style transfer models. However, detection text formality on its own may also be a useful application. This work proposes the first systematic study of formality detection methods based on current (and more classic) machine learning methods and delivers the best-performing models for public usage. We conducted three types of experiments -- monolingual, multilingual, and cross-lingual. The study shows the overcome of BiLSTM-based models over transformer-based ones for the formality classification task. We release formality detection models for several languages yielding state of the art results and possessing tested cross-lingual capabilities.