 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUTNLP at SemEval-2022 Task 6: A Comparative Analysis of Sarcasm Detection using generative-based and mutation-based data augmentation
Paper and Code
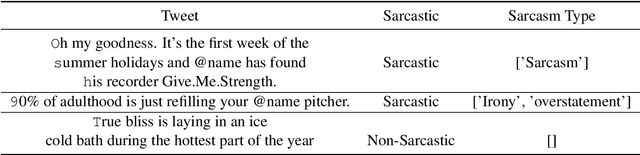
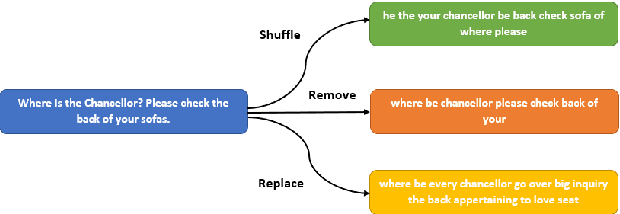
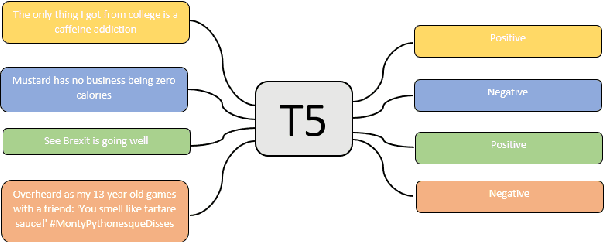
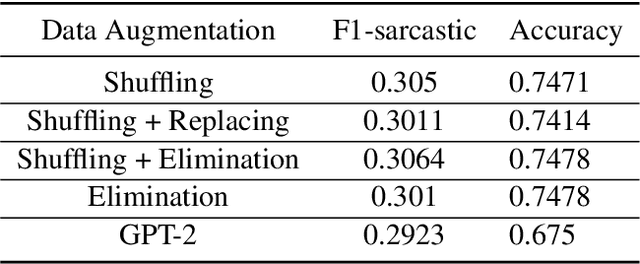
Sarcasm is a term that refers to the use of words to mock, irritate, or amuse someone. It is commonly used on social media. The metaphorical and creative nature of sarcasm presents a significant difficulty for sentiment analysis systems based on affective computing. The methodology and results of our team, UTNLP, in the SemEval-2022 shared task 6 on sarcasm detection are presented in this paper. We put different models, and data augmentation approaches to the test and report on which one works best. The tests begin with traditional machine learning models and progress to transformer-based and attention-based models. We employed data augmentation based on data mutation and data generation. Using RoBERTa and mutation-based data augmentation, our best approach achieved an F1-sarcastic of 0.38 in the competition's evaluation phase. After the competition, we fixed our model's flaws and achieved an F1-sarcastic of 0.414.