Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAGQA 2.0: An Updated Benchmark for Compositional Spatio-Temporal Reasoning
Paper and Code
Apr 12, 2022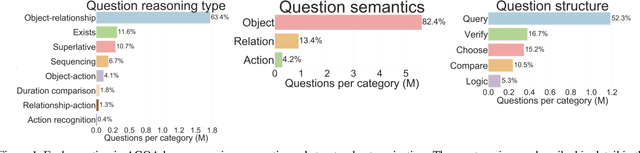
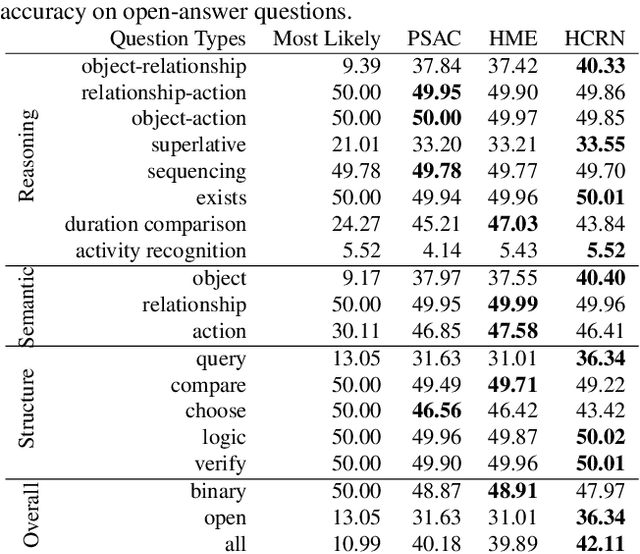
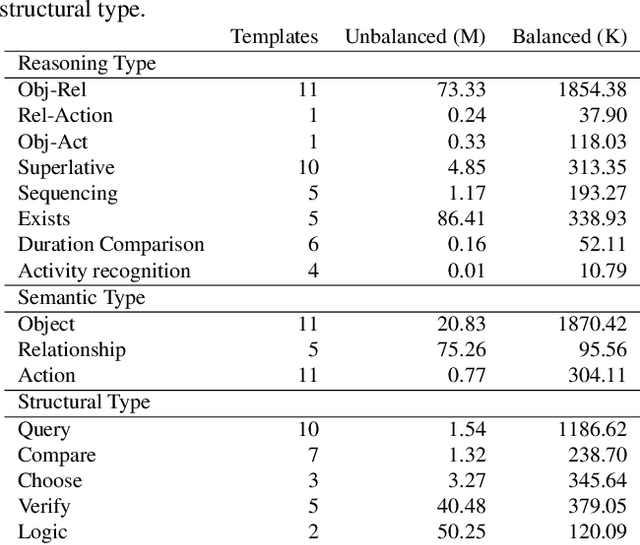
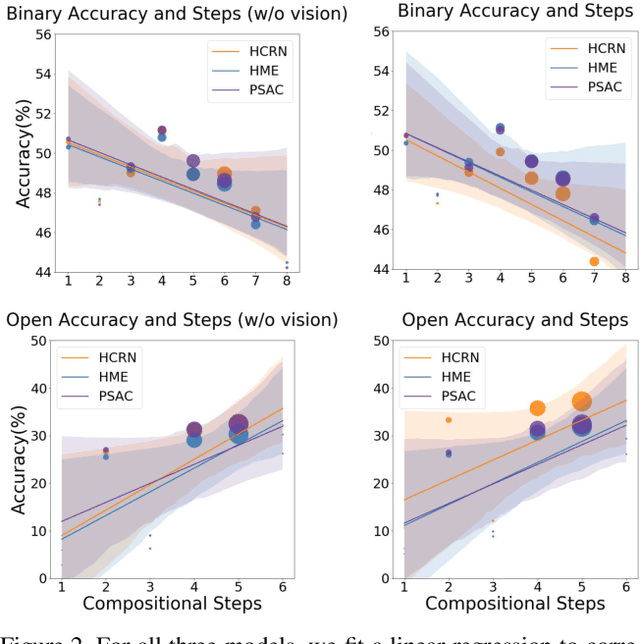
Prior benchmarks have analyzed models' answers to questions about videos in order to measure visual compositional reasoning. Action Genome Question Answering (AGQA) is one such benchmark. AGQA provides a training/test split with balanced answer distributions to reduce the effect of linguistic biases. However, some biases remain in several AGQA categories. We introduce AGQA 2.0, a version of this benchmark with several improvements, most namely a stricter balancing procedure. We then report results on the updated benchmark for all experiments.
* 7 pages, 2 figures, 7 tables, update to AGQA arXiv:2103.16002
View paper on