 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-grained Noise Control for Multispeaker Speech Synthesis
Paper and Code
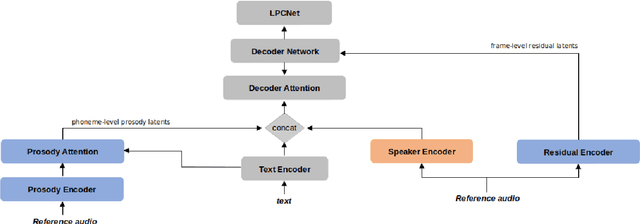
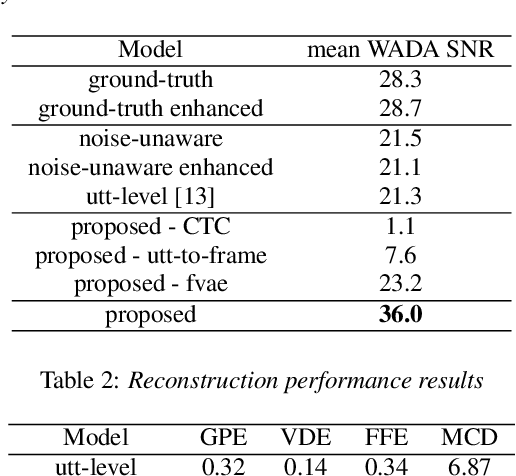
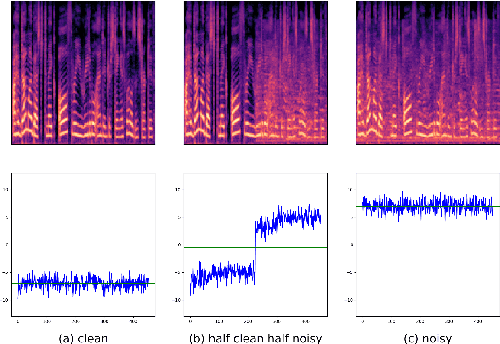
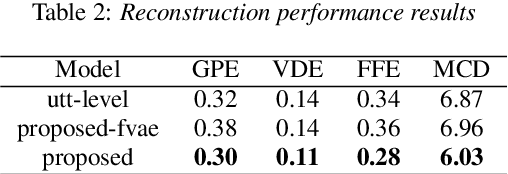
A text-to-speech (TTS) model typically factorizes speech attributes such as content, speaker and prosody into disentangled representations.Recent works aim to additionally model the acoustic conditions explicitly, in order to disentangle the primary speech factors, i.e. linguistic content, prosody and timbre from any residual factors, such as recording conditions and background noise.This paper proposes unsupervised, interpretable and fine-grained noise and prosody modeling. We incorporate adversarial training, representation bottleneck and utterance-to-frame modeling in order to learn frame-level noise representations. To the same end, we perform fine-grained prosody modeling via a Fully Hierarchical Variational AutoEncoder (FVAE) which additionally results in more expressive speech synthesis.