 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMA-Dreamer: Coordination and communication through shared imagination
Paper and Code
Apr 10, 2022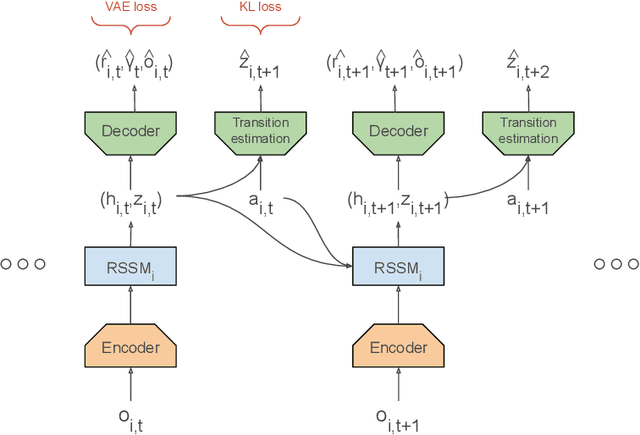

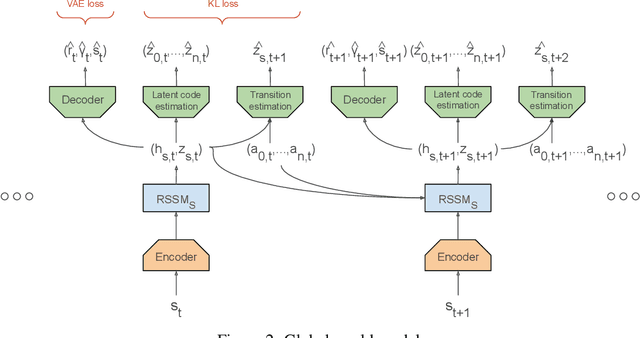

Multi-agent RL is rendered difficult due to the non-stationary nature of environment perceived by individual agents. Theoretically sound methods using the REINFORCE estimator are impeded by its high-variance, whereas value-function based methods are affected by issues stemming from their ad-hoc handling of situations like inter-agent communication. Methods like MADDPG are further constrained due to their requirement of centralized critics etc. In order to address these issues, we present MA-Dreamer, a model-based method that uses both agent-centric and global differentiable models of the environment in order to train decentralized agents' policies and critics using model-rollouts a.k.a `imagination'. Since only the model-training is done off-policy, inter-agent communication/coordination and `language emergence' can be handled in a straight-forward manner. We compare the performance of MA-Dreamer with other methods on two soccer-based games. Our experiments show that in long-term speaker-listener tasks and in cooperative games with strong partial-observability, MA-Dreamer finds a solution that makes effective use of coordination, whereas competing methods obtain marginal scores and fail outright, respectively. By effectively achieving coordination and communication under more relaxed and general conditions, out method opens the door to the study of more complex problems and population-based training.