 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplicit Parameter-free Online Learning with Truncated Linear Models
Paper and Code
Mar 19, 2022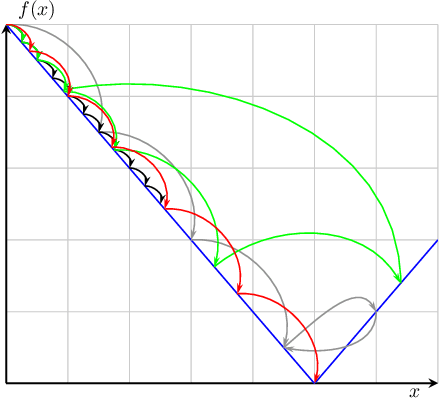
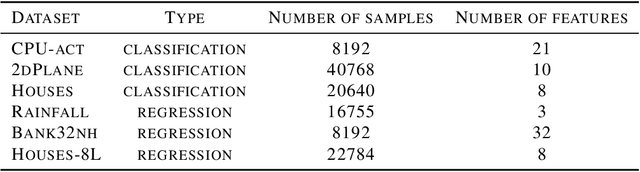
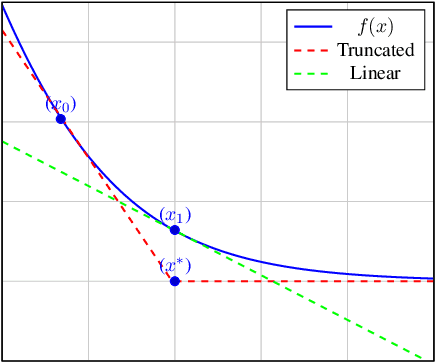
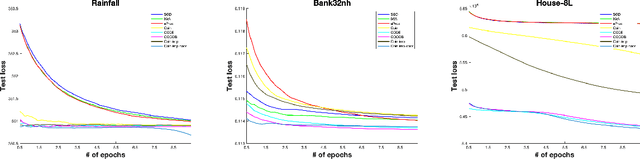
Parameter-free algorithms are online learning algorithms that do not require setting learning rates. They achieve optimal regret with respect to the distance between the initial point and any competitor. Yet, parameter-free algorithms do not take into account the geometry of the losses. Recently, in the stochastic optimization literature, it has been proposed to instead use truncated linear lower bounds, which produce better performance by more closely modeling the losses. In particular, truncated linear models greatly reduce the problem of overshooting the minimum of the loss function. Unfortunately, truncated linear models cannot be used with parameter-free algorithms because the updates become very expensive to compute. In this paper, we propose new parameter-free algorithms that can take advantage of truncated linear models through a new update that has an "implicit" flavor. Based on a novel decomposition of the regret, the new update is efficient, requires only one gradient at each step, never overshoots the minimum of the truncated model, and retains the favorable parameter-free properties. We also conduct an empirical study demonstrating the practical utility of our algorithms.