 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Linear Reinforcement Learning in Large Action Spaces: Structural Conditions and Sample-efficiency of Posterior Sampling
Paper and Code
Mar 15, 2022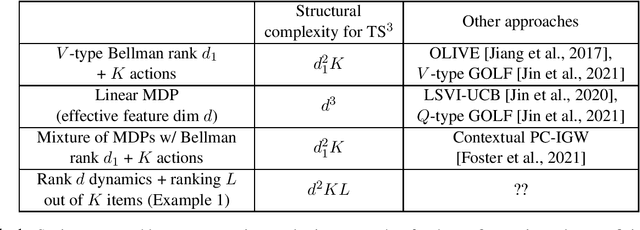
Provably sample-efficient Reinforcement Learning (RL) with rich observations and function approximation has witnessed tremendous recent progress, particularly when the underlying function approximators are linear. In this linear regime, computationally and statistically efficient methods exist where the potentially infinite state and action spaces can be captured through a known feature embedding, with the sample complexity scaling with the (intrinsic) dimension of these features. When the action space is finite, significantly more sophisticated results allow non-linear function approximation under appropriate structural constraints on the underlying RL problem, permitting for instance, the learning of good features instead of assuming access to them. In this work, we present the first result for non-linear function approximation which holds for general action spaces under a linear embeddability condition, which generalizes all linear and finite action settings. We design a novel optimistic posterior sampling strategy, TS^3 for such problems, and show worst case sample complexity guarantees that scale with a rank parameter of the RL problem, the linear embedding dimension introduced in this work and standard measures of the function class complexity.