 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan I see an Example? Active Learning the Long Tail of Attributes and Relations
Paper and Code
Mar 11, 2022
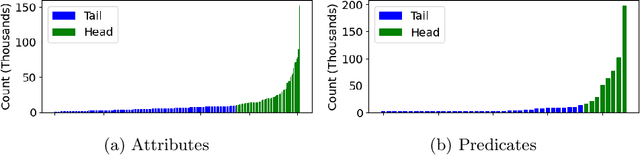
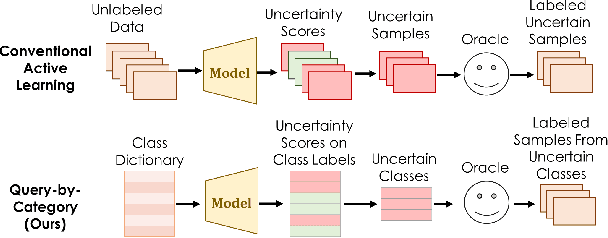
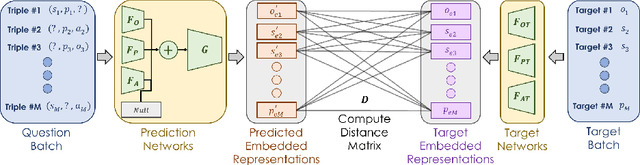
There has been significant progress in creating machine learning models that identify objects in scenes along with their associated attributes and relationships; however, there is a large gap between the best models and human capabilities. One of the major reasons for this gap is the difficulty in collecting sufficient amounts of annotated relations and attributes for training these systems. While some attributes and relations are abundant, the distribution in the natural world and existing datasets is long tailed. In this paper, we address this problem by introducing a novel incremental active learning framework that asks for attributes and relations in visual scenes. While conventional active learning methods ask for labels of specific examples, we flip this framing to allow agents to ask for examples from specific categories. Using this framing, we introduce an active sampling method that asks for examples from the tail of the data distribution and show that it outperforms classical active learning methods on Visual Genome.