 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoordinate Translator for Learning Deformable Medical Image Registration
Paper and Code
Mar 05, 2022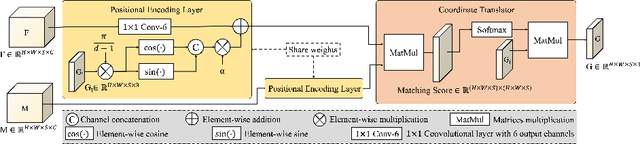
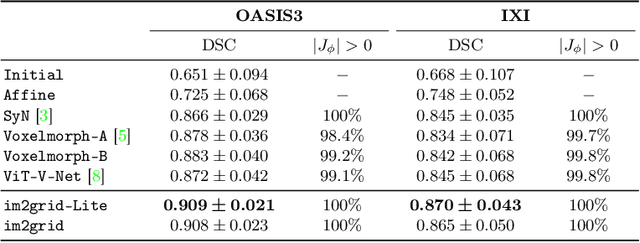
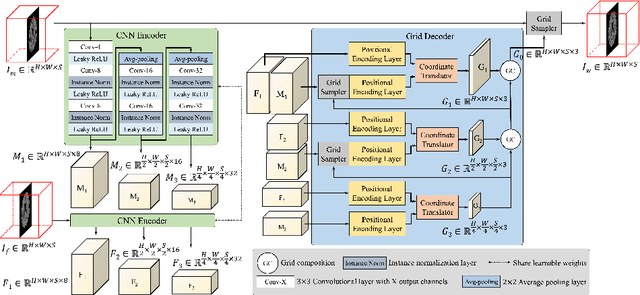
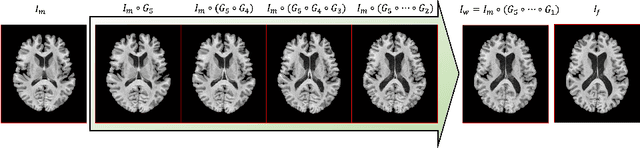
The majority of deep learning (DL) based deformable image registration methods use convolutional neural networks (CNNs) to estimate displacement fields from pairs of moving and fixed images. This, however, requires the convolutional kernels in the CNN to not only extract intensity features from the inputs but also understand image coordinate systems. We argue that the latter task is challenging for traditional CNNs, limiting their performance in registration tasks. To tackle this problem, we first introduce Coordinate Translator (CoTr), a differentiable module that identifies matched features between the fixed and moving image and outputs their coordinate correspondences without the need for training. It unloads the burden of understanding image coordinate systems for CNNs, allowing them to focus on feature extraction. We then propose a novel deformable registration network, im2grid, that uses multiple CoTr's with the hierarchical features extracted from a CNN encoder and outputs a deformation field in a coarse-to-fine fashion. We compared im2grid with the state-of-the-art DL and non-DL methods for unsupervised 3D magnetic resonance image registration. Our experiments show that im2grid outperforms these methods both qualitatively and quantitatively.