 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Continual Learning Ensembles in Neural Network Subspaces
Paper and Code
Feb 20, 2022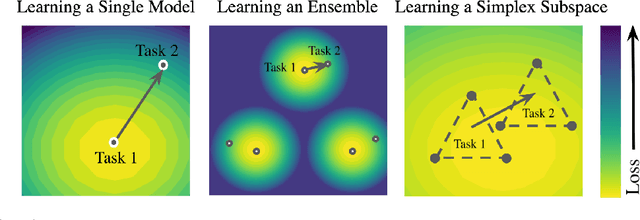
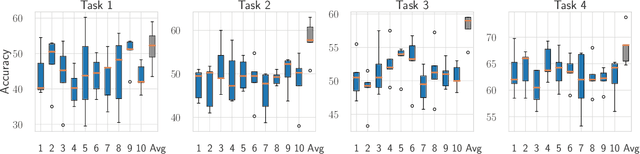

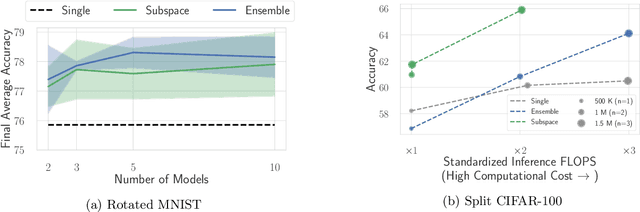
A growing body of research in continual learning focuses on the catastrophic forgetting problem. While many attempts have been made to alleviate this problem, the majority of the methods assume a single model in the continual learning setup. In this work, we question this assumption and show that employing ensemble models can be a simple yet effective method to improve continual performance. However, the training and inference cost of ensembles can increase linearly with the number of models. Motivated by this limitation, we leverage the recent advances in the deep learning optimization literature, such as mode connectivity and neural network subspaces, to derive a new method that is both computationally advantageous and can outperform the state-of-the-art continual learning algorithms.