 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Ensembles Work, But Are They Necessary?
Paper and Code
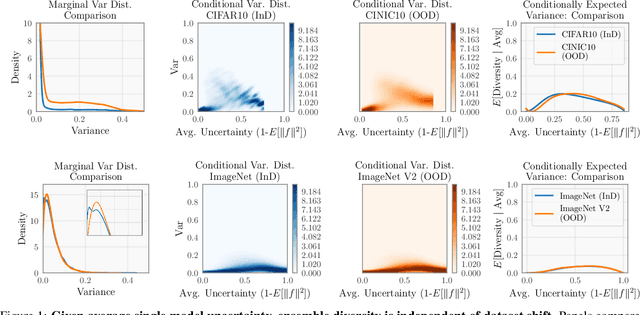
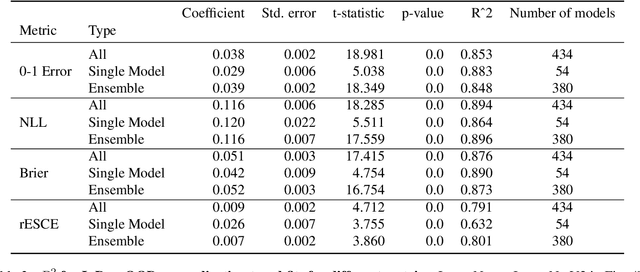
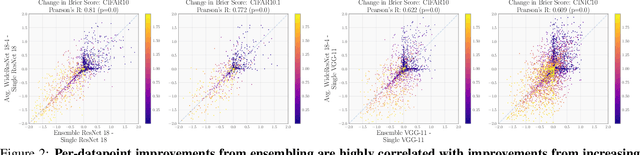
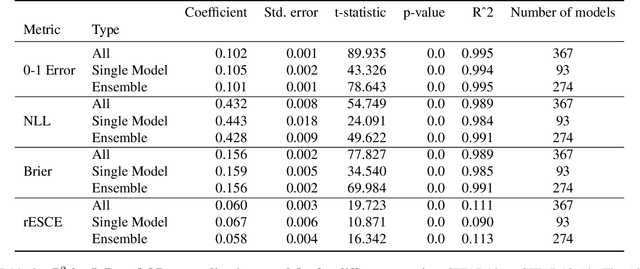
Ensembling neural networks is an effective way to increase accuracy, and can often match the performance of larger models. This observation poses a natural question: given the choice between a deep ensemble and a single neural network with similar accuracy, is one preferable over the other? Recent work suggests that deep ensembles may offer benefits beyond predictive power: namely, uncertainty quantification and robustness to dataset shift. In this work, we demonstrate limitations to these purported benefits, and show that a single (but larger) neural network can replicate these qualities. First, we show that ensemble diversity, by any metric, does not meaningfully contribute to an ensemble's ability to detect out-of-distribution (OOD) data, and that one can estimate ensemble diversity by measuring the relative improvement of a single larger model. Second, we show that the OOD performance afforded by ensembles is strongly determined by their in-distribution (InD) performance, and -- in this sense -- is not indicative of any "effective robustness". While deep ensembles are a practical way to achieve performance improvement (in agreement with prior work), our results show that they may be a tool of convenience rather than a fundamentally better model class.