Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrace norm regularization for multi-task learning with scarce data
Paper and Code

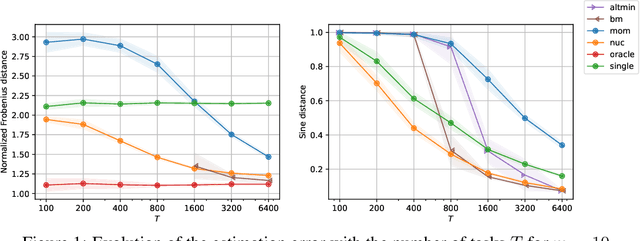
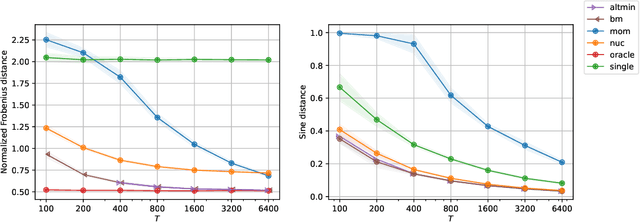
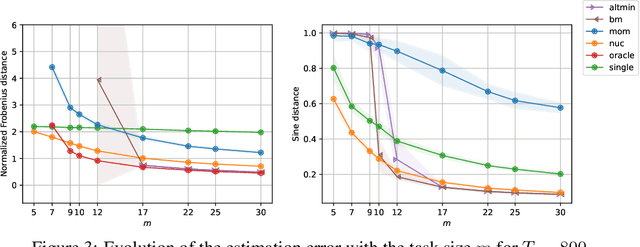
Multi-task learning leverages structural similarities between multiple tasks to learn despite very few samples. Motivated by the recent success of neural networks applied to data-scarce tasks, we consider a linear low-dimensional shared representation model. Despite an extensive literature, existing theoretical results either guarantee weak estimation rates or require a large number of samples per task. This work provides the first estimation error bound for the trace norm regularized estimator when the number of samples per task is small. The advantages of trace norm regularization for learning data-scarce tasks extend to meta-learning and are confirmed empirically on synthetic datasets.
View paper on