 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Sample Efficiency of Value Based Models Using Attention and Vision Transformers
Paper and Code
Feb 01, 2022
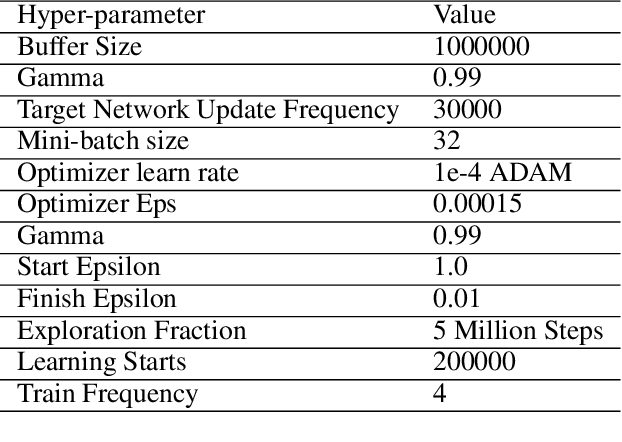
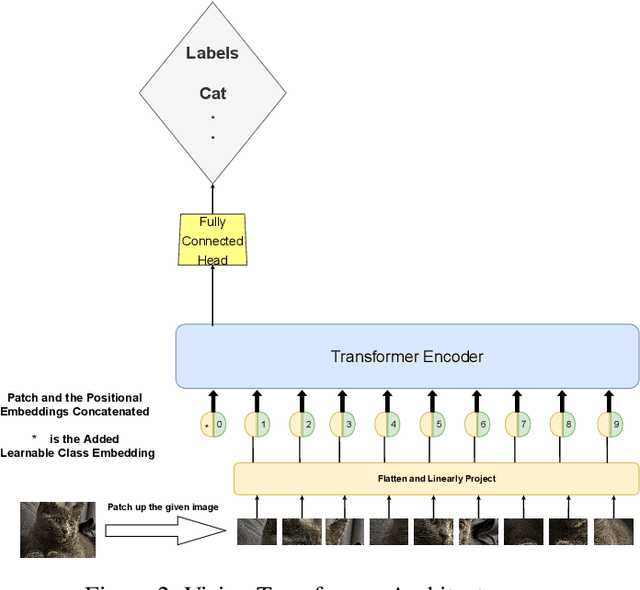
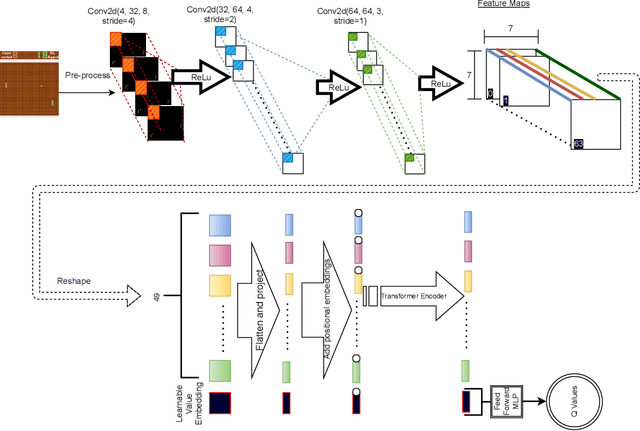
Much of recent Deep Reinforcement Learning success is owed to the neural architecture's potential to learn and use effective internal representations of the world. While many current algorithms access a simulator to train with a large amount of data, in realistic settings, including while playing games that may be played against people, collecting experience can be quite costly. In this paper, we introduce a deep reinforcement learning architecture whose purpose is to increase sample efficiency without sacrificing performance. We design this architecture by incorporating advances achieved in recent years in the field of Natural Language Processing and Computer Vision. Specifically, we propose a visually attentive model that uses transformers to learn a self-attention mechanism on the feature maps of the state representation, while simultaneously optimizing return. We demonstrate empirically that this architecture improves sample complexity for several Atari environments, while also achieving better performance in some of the games.