 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Cleaner Document-Oriented Multilingual Crawled Corpus
Paper and Code
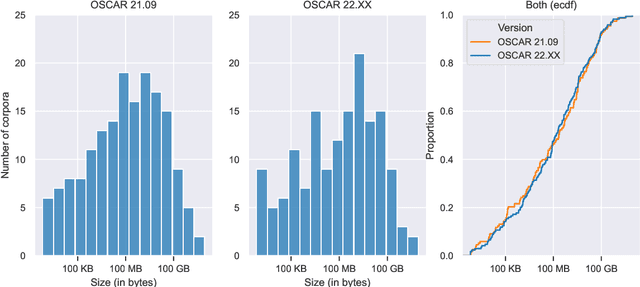
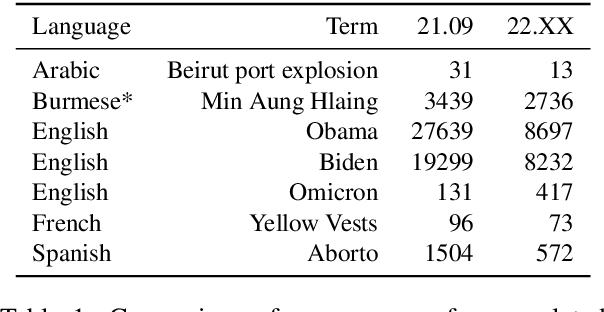
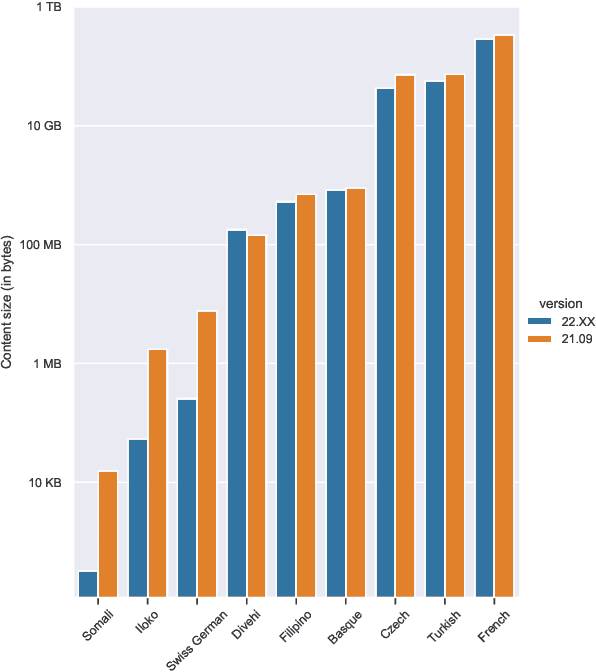
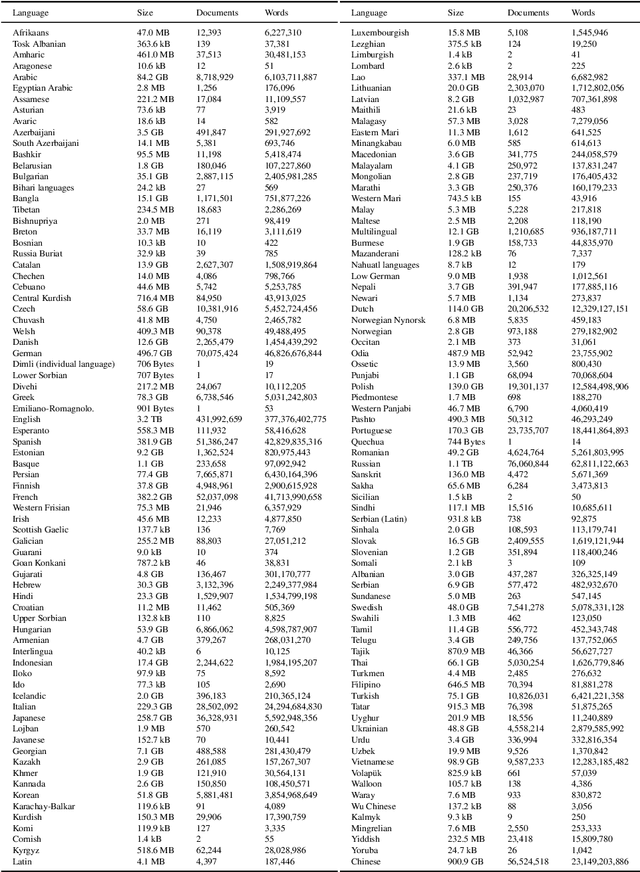
The need for raw large raw corpora has dramatically increased in recent years with the introduction of transfer learning and semi-supervised learning methods to Natural Language Processing. And while there have been some recent attempts to manually curate the amount of data necessary to train large language models, the main way to obtain this data is still through automatic web crawling. In this paper we take the existing multilingual web corpus OSCAR and its pipeline Ungoliant that extracts and classifies data from Common Crawl at the line level, and propose a set of improvements and automatic annotations in order to produce a new document-oriented version of OSCAR that could prove more suitable to pre-train large generative language models as well as hopefully other applications in Natural Language Processing and Digital Humanities.