 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWANLI: Worker and AI Collaboration for Natural Language Inference Dataset Creation
Paper and Code
Jan 16, 2022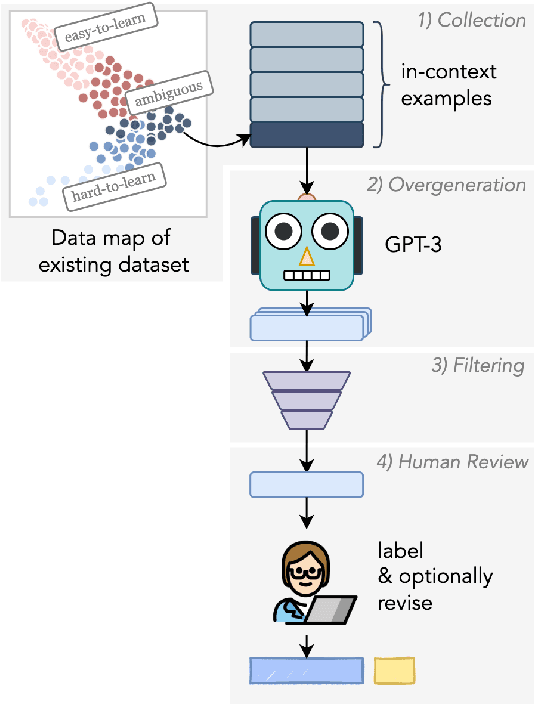
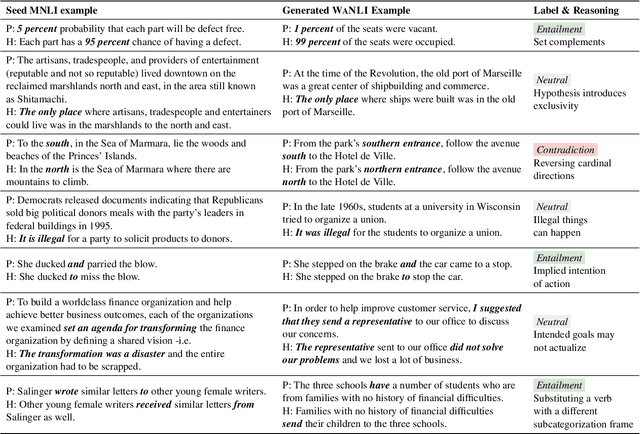
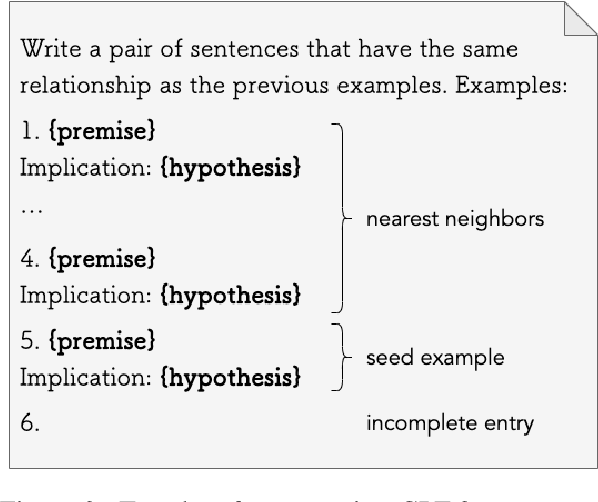
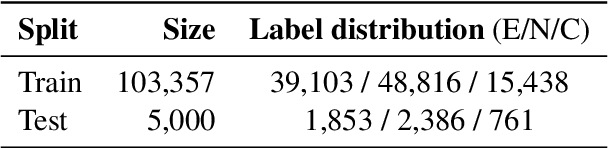
A recurring challenge of crowdsourcing NLP datasets at scale is that human writers often rely on repetitive patterns when crafting examples, leading to a lack of linguistic diversity. We introduce a novel paradigm for dataset creation based on human and machine collaboration, which brings together the generative strength of language models and the evaluative strength of humans. Starting with an existing dataset, MultiNLI, our approach uses dataset cartography to automatically identify examples that demonstrate challenging reasoning patterns, and instructs GPT-3 to compose new examples with similar patterns. Machine generated examples are then automatically filtered, and finally revised and labeled by human crowdworkers to ensure quality. The resulting dataset, WANLI, consists of 108,357 natural language inference (NLI) examples that present unique empirical strengths over existing NLI datasets. Remarkably, training a model on WANLI instead of MNLI (which is 4 times larger) improves performance on seven out-of-domain test sets we consider, including by 11% on HANS and 9% on Adversarial NLI. Moreover, combining MNLI with WANLI is more effective than combining with other augmentation sets that have been introduced. Our results demonstrate the potential of natural language generation techniques to curate NLP datasets of enhanced quality and diversity.