 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining Prediction Uncertainty of Pre-trained Language Models by Detecting Uncertain Words in Inputs
Paper and Code
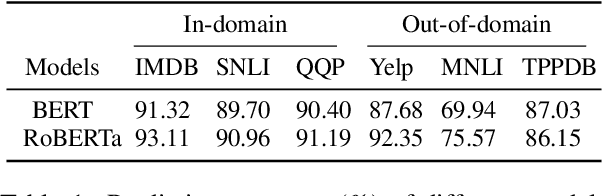
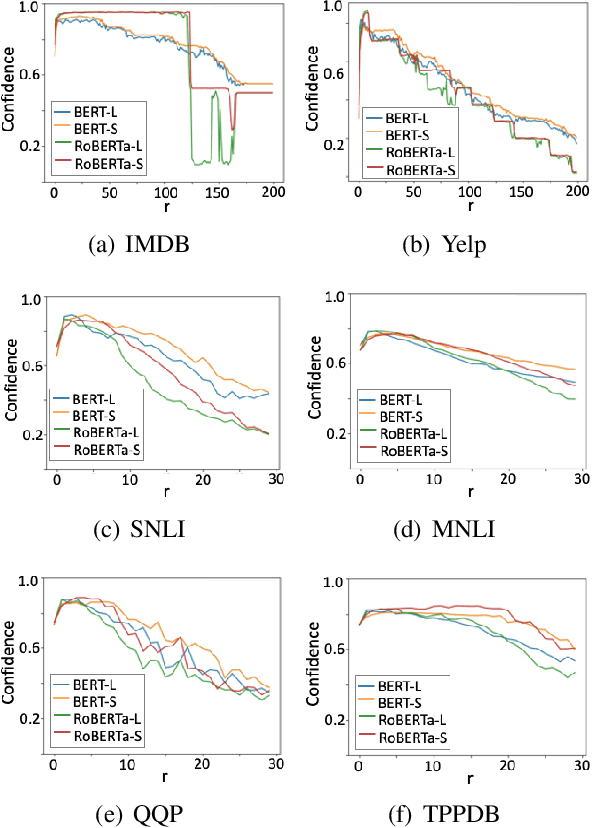

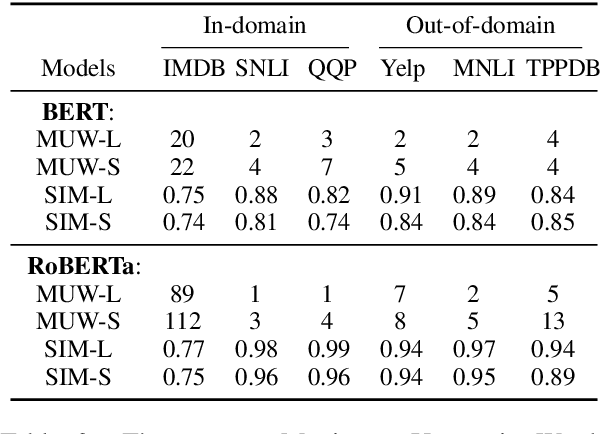
Estimating the predictive uncertainty of pre-trained language models is important for increasing their trustworthiness in NLP. Although many previous works focus on quantifying prediction uncertainty, there is little work on explaining the uncertainty. This paper pushes a step further on explaining uncertain predictions of post-calibrated pre-trained language models. We adapt two perturbation-based post-hoc interpretation methods, Leave-one-out and Sampling Shapley, to identify words in inputs that cause the uncertainty in predictions. We test the proposed methods on BERT and RoBERTa with three tasks: sentiment classification, natural language inference, and paraphrase identification, in both in-domain and out-of-domain settings. Experiments show that both methods consistently capture words in inputs that cause prediction uncertainty.