 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTiltedBERT: Resource Adjustable Version of BERT
Paper and Code
Jan 14, 2022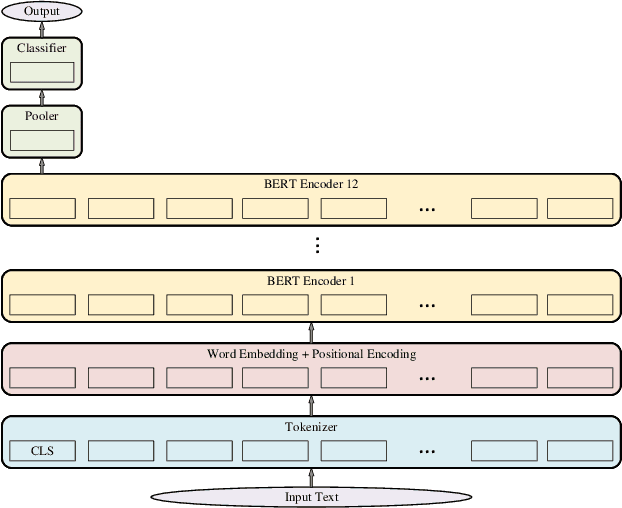
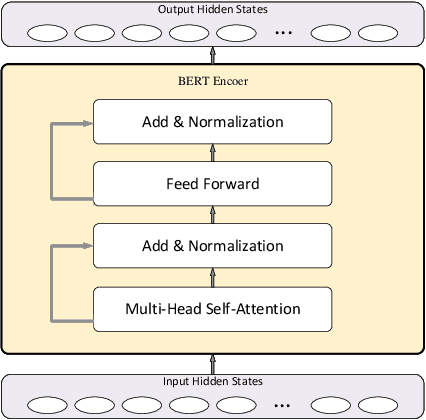
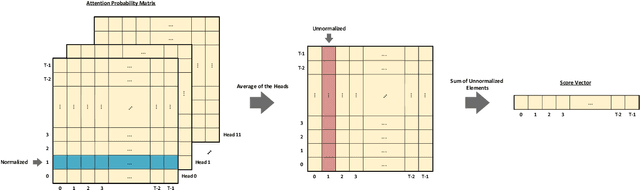
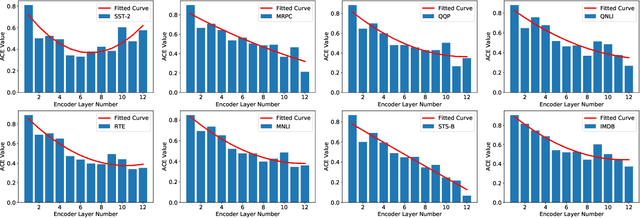
In this paper, we proposed a novel adjustable finetuning method that improves the training and inference time of the BERT model on downstream tasks. In the proposed method, we first detect more important word vectors in each layer by our proposed redundancy metric and then eliminate the less important word vectors with our proposed strategy. In our method, the word vector elimination rate in each layer is controlled by the Tilt-Rate hyper-parameter, and the model learns to work with a considerably lower number of Floating Point Operations (FLOPs) than the original BERTbase model. Our proposed method does not need any extra training steps, and also it can be generalized to other transformer-based models. We perform extensive experiments that show the word vectors in higher layers have an impressive amount of redundancy that can be eliminated and decrease the training and inference time. Experimental results on extensive sentiment analysis, classification and regression datasets, and benchmarks like IMDB and GLUE showed that our proposed method is effective in various datasets. By applying our method on the BERTbase model, we decrease the inference time up to 5.3 times with less than 0.85% accuracy degradation on average. After the fine-tuning stage, the inference time of our model can be adjusted with our method offline-tuning property for a wide range of the Tilt-Rate value selections. Also, we propose a mathematical speedup analysis that can estimate the speedup of our method accurately. With the help of this analysis, the proper Tilt-Rate value can be selected before fine-tuning or while offline-tuning stages.