 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry-Preserving Aggregation for Mixture-of-Experts Embedding Models
Feb 15, 2026Mixture-of-Experts (MoE) embedding models combine expert outputs using weighted linear summation, implicitly assuming a linear subspace structure in the embedding space. This assumption is shown to be inconsistent with the geometry of expert representations. Geometric analysis of a modern MoE embedding model reveals that expert outputs lie on a shared hyperspherical manifold characterized by tightly concentrated norms and substantial angular separation. Under this geometry, linear aggregation induces inward collapse toward the manifold interior, distorting vector magnitude and direction and reducing embedding comparability. To address this inconsistency, Spherical Barycentric Aggregation (SBA) is introduced as a geometry-preserving aggregation operator that separates radial and angular components to maintain hyperspherical structure while remaining fully compatible with existing routing mechanisms. Experiments on selected tasks from the Massive Text Embedding Benchmark (MTEB), including semantic similarity, clustering, and duplicate question detection, demonstrate consistent performance improvements with identical training cost and full stability. Additional geometric analyses confirm that SBA prevents aggregation-induced collapse and preserves hyperspherical consistency, highlighting the importance of geometry-aware aggregation in MoE embedding architectures.
TiltedBERT: Resource Adjustable Version of BERT
Jan 14, 2022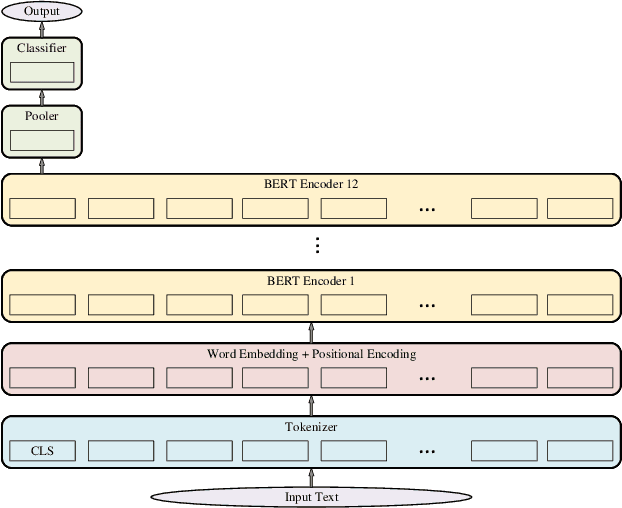
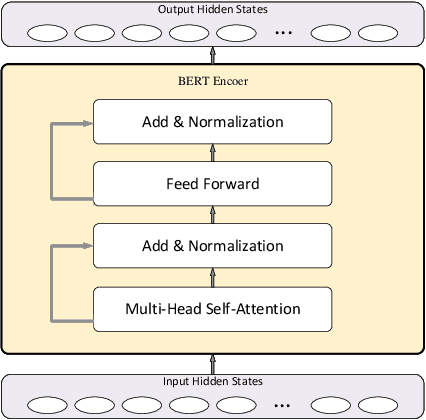
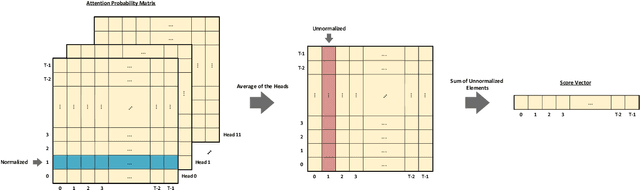
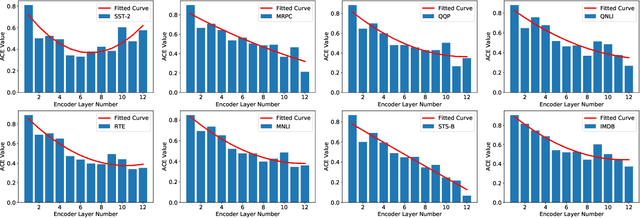
In this paper, we proposed a novel adjustable finetuning method that improves the training and inference time of the BERT model on downstream tasks. In the proposed method, we first detect more important word vectors in each layer by our proposed redundancy metric and then eliminate the less important word vectors with our proposed strategy. In our method, the word vector elimination rate in each layer is controlled by the Tilt-Rate hyper-parameter, and the model learns to work with a considerably lower number of Floating Point Operations (FLOPs) than the original BERTbase model. Our proposed method does not need any extra training steps, and also it can be generalized to other transformer-based models. We perform extensive experiments that show the word vectors in higher layers have an impressive amount of redundancy that can be eliminated and decrease the training and inference time. Experimental results on extensive sentiment analysis, classification and regression datasets, and benchmarks like IMDB and GLUE showed that our proposed method is effective in various datasets. By applying our method on the BERTbase model, we decrease the inference time up to 5.3 times with less than 0.85% accuracy degradation on average. After the fine-tuning stage, the inference time of our model can be adjusted with our method offline-tuning property for a wide range of the Tilt-Rate value selections. Also, we propose a mathematical speedup analysis that can estimate the speedup of our method accurately. With the help of this analysis, the proper Tilt-Rate value can be selected before fine-tuning or while offline-tuning stages.