 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing the Communication-Accuracy Trade-off in Federated Learning with Rate-Distortion Theory
Paper and Code
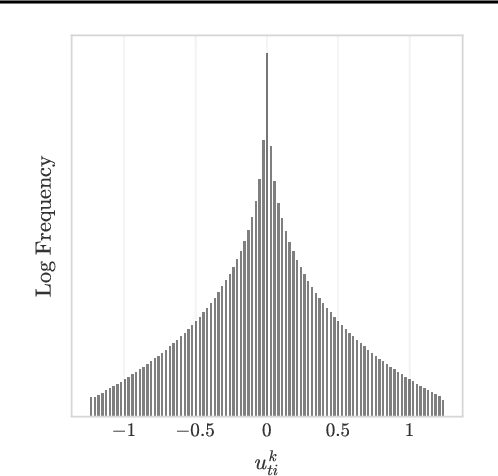

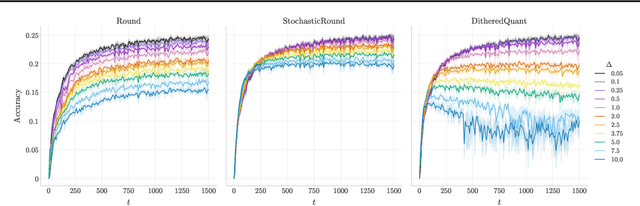
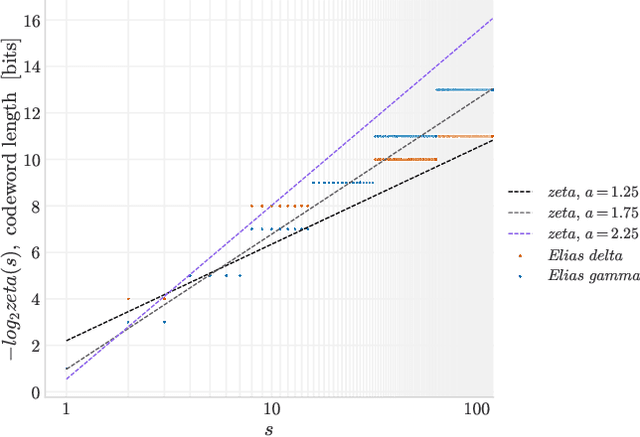
A significant bottleneck in federated learning is the network communication cost of sending model updates from client devices to the central server. We propose a method to reduce this cost. Our method encodes quantized updates with an appropriate universal code, taking into account their empirical distribution. Because quantization introduces error, we select quantization levels by optimizing for the desired trade-off in average total bitrate and gradient distortion. We demonstrate empirically that in spite of the non-i.i.d. nature of federated learning, the rate-distortion frontier is consistent across datasets, optimizers, clients and training rounds, and within each setting, distortion reliably predicts model performance. This allows for a remarkably simple compression scheme that is near-optimal in many use cases, and outperforms Top-K, DRIVE, 3LC and QSGD on the Stack Overflow next-word prediction benchmark.