 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Architecture Search for Inversion
Paper and Code
Jan 05, 2022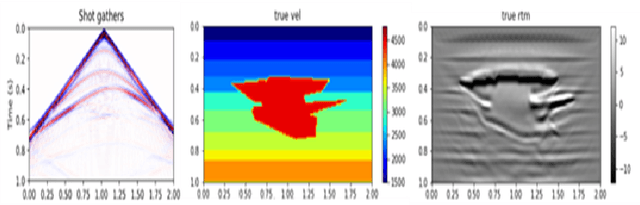

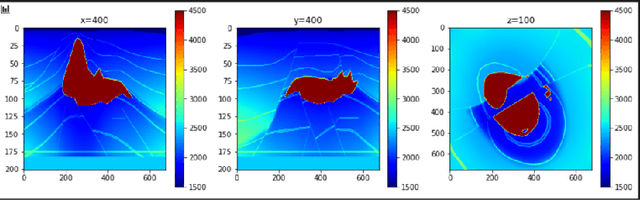
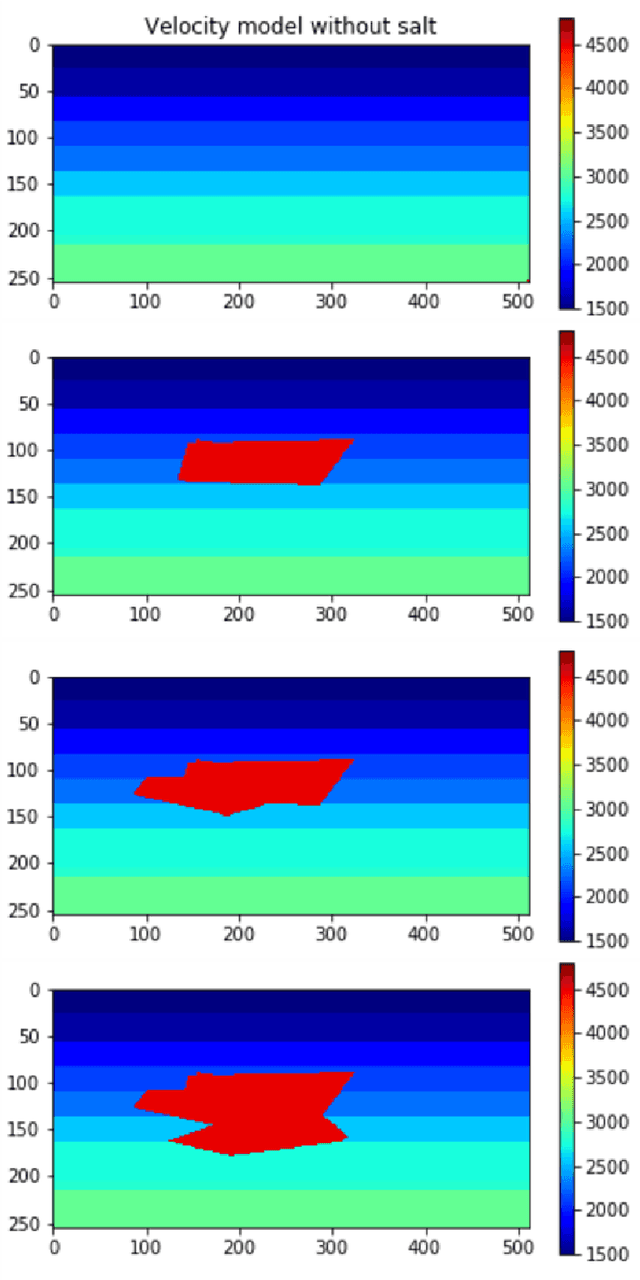
Over the year, people have been using deep learning to tackle inversion problems, and we see the framework has been applied to build relationship between recording wavefield and velocity (Yang et al., 2016). Here we will extend the work from 2 perspectives, one is deriving a more appropriate loss function, as we now, pixel-2-pixel comparison might not be the best choice to characterize image structure, and we will elaborate on how to construct cost function to capture high level feature to enhance the model performance. Another dimension is searching for the more appropriate neural architecture, which is a subset of an even bigger picture, the automatic machine learning, or AutoML. There are several famous networks, U-net, ResNet (He et al., 2016) and DenseNet (Huang et al., 2017), and they achieve phenomenal results for certain problems, yet it's hard to argue they are the best for inversion problems without thoroughly searching within certain space. Here we will be showing our architecture search results for inversion.