 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-Vocabulary Image Segmentation
Paper and Code
Dec 22, 2021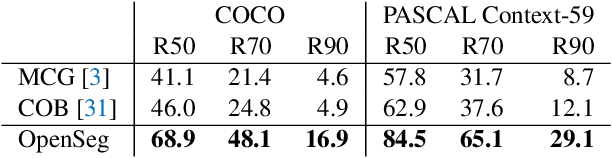

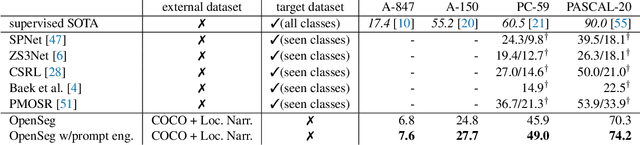
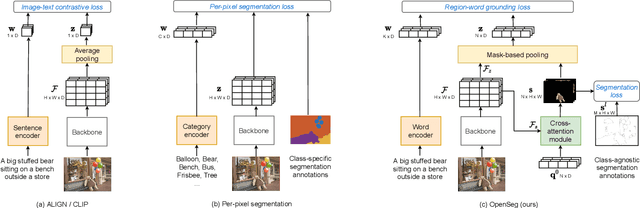
We design an open-vocabulary image segmentation model to organize an image into meaningful regions indicated by arbitrary texts. We identify that recent open-vocabulary models can not localize visual concepts well despite recognizing what are in an image. We argue that these models miss an important step of visual grouping, which organizes pixels into groups before learning visual-semantic alignments. We propose OpenSeg to address the above issue. First, it learns to propose segmentation masks for possible organizations. Then it learns visual-semantic alignments by aligning each word in a caption to one or a few predicted masks. We find the mask representations are the key to support learning from captions, making it possible to scale up the dataset and vocabulary sizes. Our work is the first to perform zero-shot transfer on holdout segmentation datasets. We set up two strong baselines by applying class activation maps or fine-tuning with pixel-wise labels on a pre-trained ALIGN model. OpenSeg outperforms these baselines by 3.4 mIoU on PASCAL-Context (459 classes) and 2.7 mIoU on ADE-20k (847 classes).