 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLerna: Transformer Architectures for Configuring Error Correction Tools for Short- and Long-Read Genome Sequencing
Paper and Code
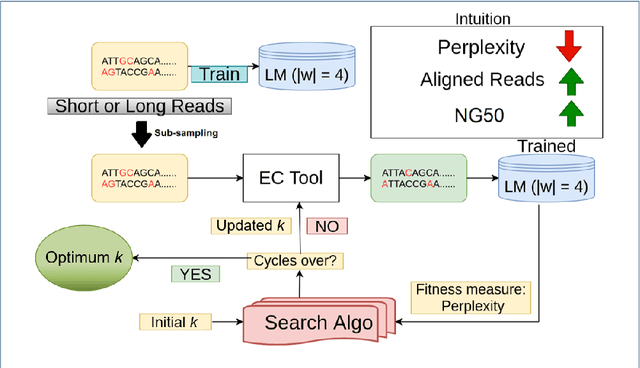
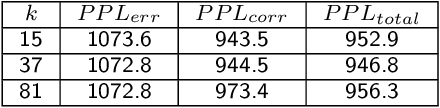
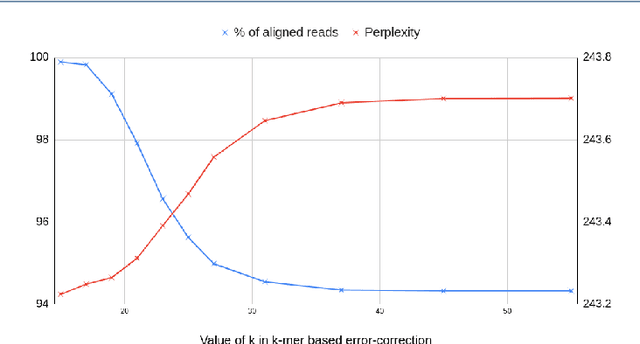
Sequencing technologies are prone to errors, making error correction (EC) necessary for downstream applications. EC tools need to be manually configured for optimal performance. We find that the optimal parameters (e.g., k-mer size) are both tool- and dataset-dependent. Moreover, evaluating the performance (i.e., Alignment-rate or Gain) of a given tool usually relies on a reference genome, but quality reference genomes are not always available. We introduce Lerna for the automated configuration of k-mer-based EC tools. Lerna first creates a language model (LM) of the uncorrected genomic reads; then, calculates the perplexity metric to evaluate the corrected reads for different parameter choices. Next, it finds the one that produces the highest alignment rate without using a reference genome. The fundamental intuition of our approach is that the perplexity metric is inversely correlated with the quality of the assembly after error correction. Results: First, we show that the best k-mer value can vary for different datasets, even for the same EC tool. Second, we show the gains of our LM using its component attention-based transformers. We show the model's estimation of the perplexity metric before and after error correction. The lower the perplexity after correction, the better the k-mer size. We also show that the alignment rate and assembly quality computed for the corrected reads are strongly negatively correlated with the perplexity, enabling the automated selection of k-mer values for better error correction, and hence, improved assembly quality. Additionally, we show that our attention-based models have significant runtime improvement for the entire pipeline -- 18X faster than previous works, due to parallelizing the attention mechanism and the use of JIT compilation for GPU inferencing.