 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQAFactEval: Improved QA-Based Factual Consistency Evaluation for Summarization
Paper and Code

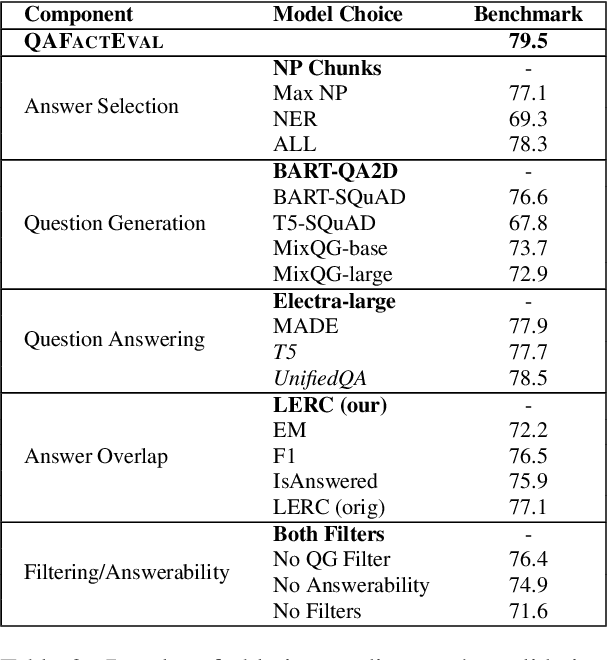
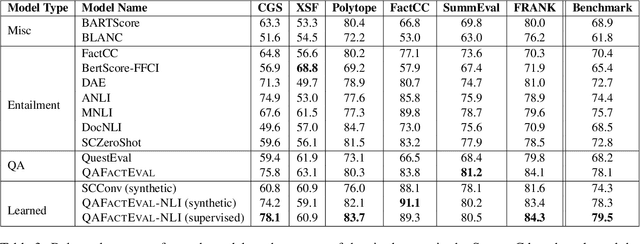

Factual consistency is an essential quality of text summarization models in practical settings. Existing work in evaluating this dimension can be broadly categorized into two lines of research, entailment-based metrics and question answering (QA)-based metrics. However, differing experimental setups presented in recent work lead to contrasting conclusions as to which paradigm performs best. In this work, we conduct an extensive comparison of entailment and QA-based metrics, demonstrating that carefully choosing the components of a QA-based metric is critical to performance. Building on those insights, we propose an optimized metric, which we call QAFactEval, that leads to a 15% average improvement over previous QA-based metrics on the SummaC factual consistency benchmark. Our solution improves upon the best-performing entailment-based metric and achieves state-of-the-art performance on this benchmark. Furthermore, we find that QA-based and entailment-based metrics offer complementary signals and combine the two into a single, learned metric for further performance boost. Through qualitative and quantitative analyses, we point to question generation and answerability classification as two critical components for future work in QA-based metrics.