 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Learning In Environments With Polynomial Mixing Times
Paper and Code
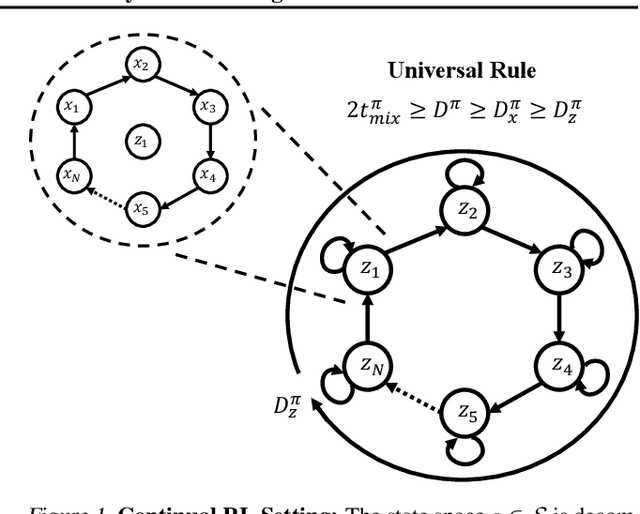

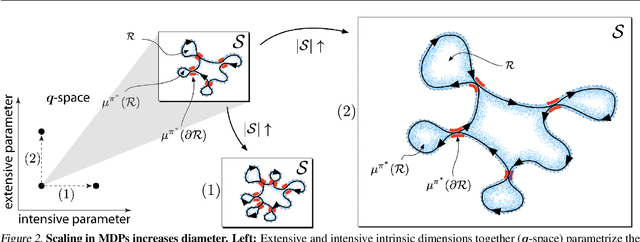
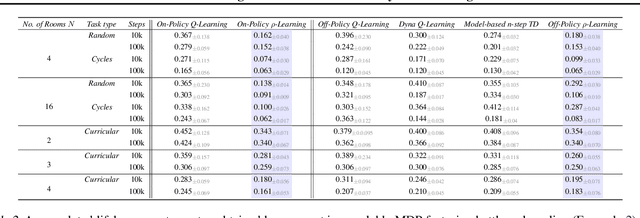
The mixing time of the Markov chain induced by a policy limits performance in real-world continual learning scenarios. Yet, the effect of mixing times on learning in continual reinforcement learning (RL) remains underexplored. In this paper, we characterize problems that are of long-term interest to the development of continual RL, which we call scalable MDPs, through the lens of mixing times. In particular, we establish that scalable MDPs have mixing times that scale polynomially with the size of the problem. We go on to demonstrate that polynomial mixing times present significant difficulties for existing approaches and propose a family of model-based algorithms that speed up learning by directly optimizing for the average reward through a novel bootstrapping procedure. Finally, we perform empirical regret analysis of our proposed approaches, demonstrating clear improvements over baselines and also how scalable MDPs can be used for analysis of RL algorithms as mixing times scale.