 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePM-MMUT: Boosted Phone-mask Data Augmentation using Multi-modeing Unit Training for Robust Uyghur E2E Speech Recognition
Paper and Code
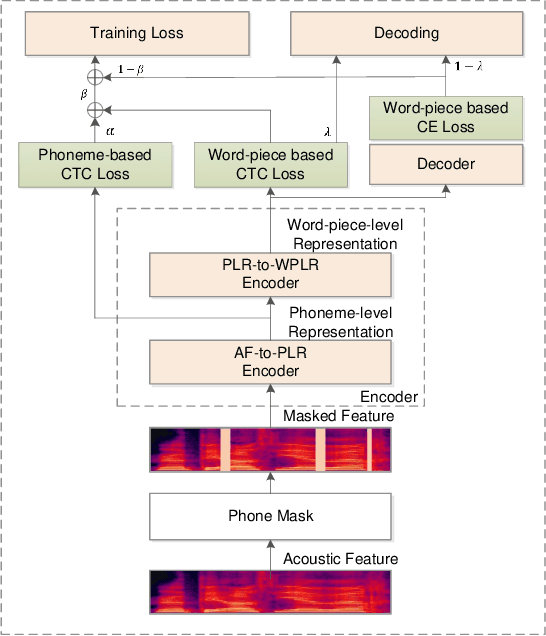
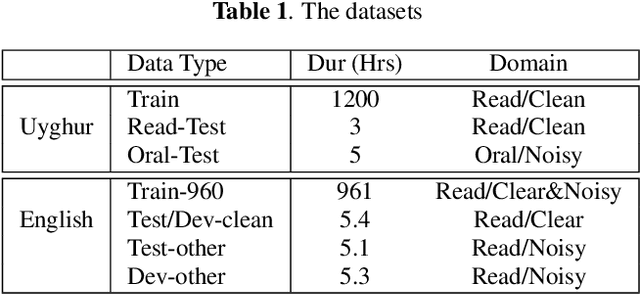
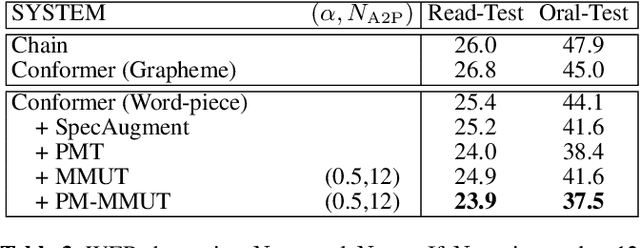
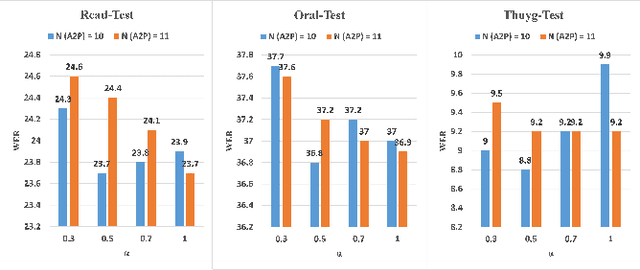
Consonant and vowel reduction are often encountered in Uyghur speech, which might cause performance degradation in Uyghur automatic speech recognition (ASR). Our recently proposed learning strategy based on masking, Phone Masking Training (PMT), alleviates the impact of such phenomenon in Uyghur ASR. Although PMT achieves remarkably improvements, there still exists room for further gains due to the granularity mismatch between masking unit of PMT (phoneme) and modeling unit (word-piece). To boost the performance of PMT, we propose multi-modeling unit training (MMUT) architecture fusion with PMT (PM-MMUT). The idea of MMUT framework is to split the Encoder into two parts including acoustic feature sequences to phoneme-level representation (AF-to-PLR) and phoneme-level representation to word-piece-level representation (PLR-to-WPLR). It allows AF-to-PLR to be optimized by an intermediate phoneme-based CTC loss to learn the rich phoneme-level context information brought by PMT. Experi-mental results on Uyghur ASR show that the proposed approaches improve significantly, outperforming the pure PMT (reduction WER from 24.0 to 23.7 on Read-Test and from 38.4 to 36.8 on Oral-Test respectively). We also conduct experiments on the 960-hour Librispeech benchmark using ESPnet1, which achieves about 10% relative WER reduction on all the test sets without LM fusion comparing with the latest official ESPnet1 pre-trained model.