 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Structured Inference with Randomization
Paper and Code

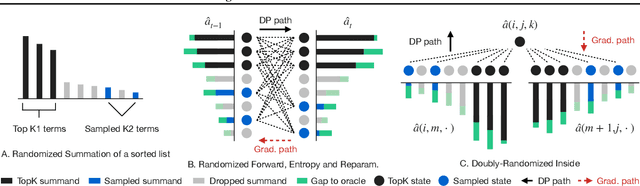
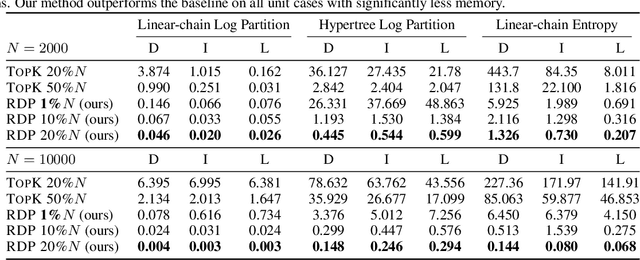
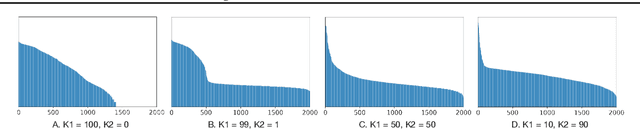
The scale of the state space of discrete graphical models is crucial for model capacity in the era of deep learning. Existing dynamic programming (DP) based inference typically works with a small number of states (usually less than hundreds). In this work, we propose a family of randomized dynamic programming (RDP) algorithms for scaling structured models to tens of thousands of latent states. Our method is widely applicable to classical DP-based inference (partition, marginal, reparameterization, entropy, .etc) and different graph structures (chains, trees, and more general hypergraphs). It is also compatible with automatic differentiation so can be integrated with neural networks seamlessly and learned with gradient-based optimizers. Our core technique is randomization, which is to restrict and reweight DP on a small selected subset of nodes, leading to computation reduction by orders of magnitudes. We further achieve low bias and variance with Rao-Blackwellization and importance sampling. Experiments on different inferences over different graphs demonstrate the accuracy and efficiency of our methods. Furthermore, when using RDP to train a scaled structured VAE, it outperforms baselines in terms of test likelihood and successfully prevents posterior collapse.