 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample Prior Guided Robust Model Learning to Suppress Noisy Labels
Paper and Code
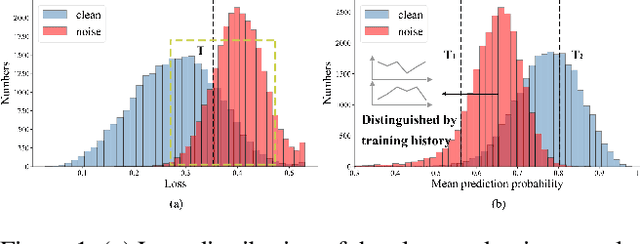
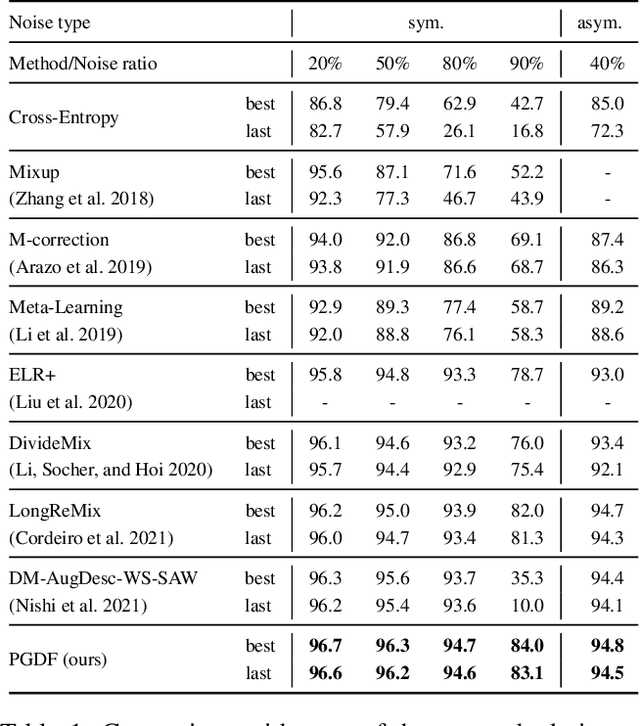
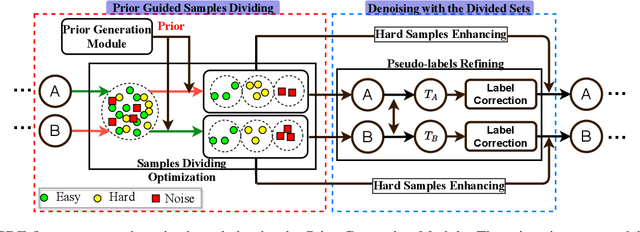
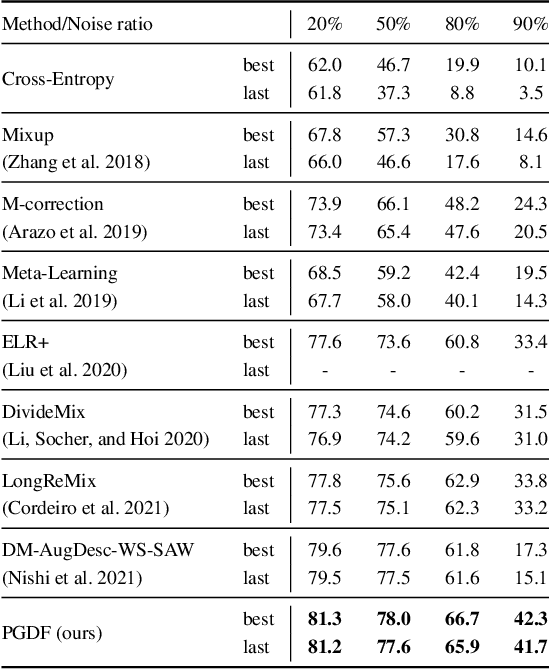
Imperfect labels are ubiquitous in real-world datasets and seriously harm the model performance. Several recent effective methods for handling noisy labels have two key steps: 1) dividing samples into cleanly labeled and wrongly labeled sets by training loss, 2) using semi-supervised methods to generate pseudo-labels for samples in the wrongly labeled set. However, current methods always hurt the informative hard samples due to the similar loss distribution between the hard samples and the noisy ones. In this paper, we proposed PGDF (Prior Guided Denoising Framework), a novel framework to learn a deep model to suppress noise by generating the samples' prior knowledge, which is integrated into both dividing samples step and semi-supervised step. Our framework can save more informative hard clean samples into the cleanly labeled set. Besides, our framework also promotes the quality of pseudo-labels during the semi-supervised step by suppressing the noise in the current pseudo-labels generating scheme. To further enhance the hard samples, we reweight the samples in the cleanly labeled set during training. We evaluated our method using synthetic datasets based on CIFAR-10 and CIFAR-100, as well as on the real-world datasets WebVision and Clothing1M. The results demonstrate substantial improvements over state-of-the-art methods.