 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory-efficient array redistribution through portable collective communication
Paper and Code
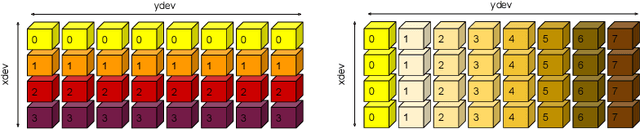
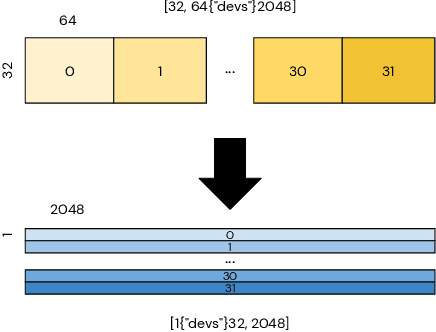
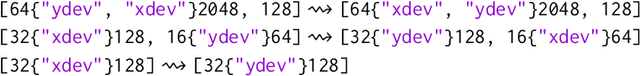

Modern large-scale deep learning workloads highlight the need for parallel execution across many devices in order to fit model data into hardware accelerator memories. In these settings, array redistribution may be required during a computation, but can also become a bottleneck if not done efficiently. In this paper we address the problem of redistributing multi-dimensional array data in SPMD computations, the most prevalent form of parallelism in deep learning. We present a type-directed approach to synthesizing array redistributions as sequences of MPI-style collective operations. We prove formally that our synthesized redistributions are memory-efficient and perform no excessive data transfers. Array redistribution for SPMD computations using collective operations has also been implemented in the context of the XLA SPMD partitioner, a production-grade tool for partitioning programs across accelerator systems. We evaluate our approach against the XLA implementation and find that our approach delivers a geometric mean speedup of $1.22\times$, with maximum speedups as a high as $5.7\times$, while offering provable memory guarantees, making our system particularly appealing for large-scale models.