 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixed Precision DNN Qunatization for Overlapped Speech Separation and Recognition
Paper and Code
Nov 29, 2021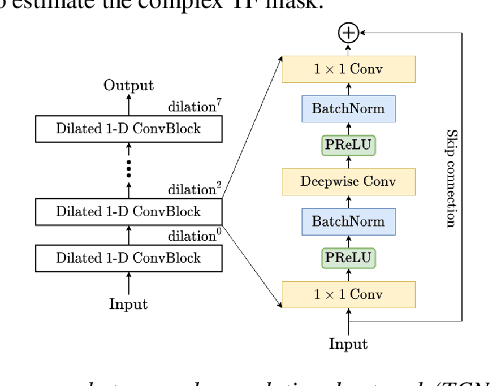
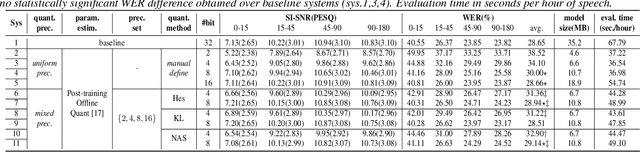
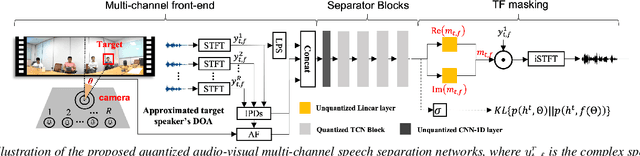
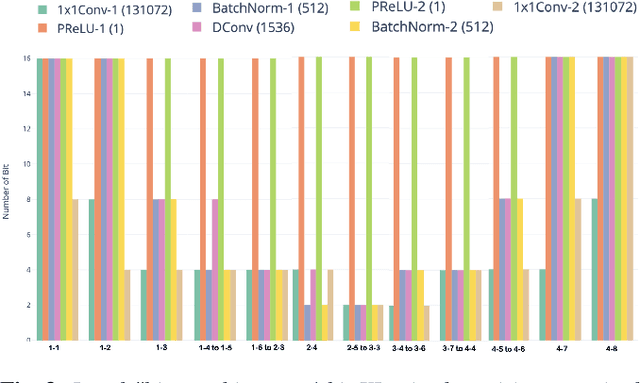
Recognition of overlapped speech has been a highly challenging task to date. State-of-the-art multi-channel speech separation system are becoming increasingly complex and expensive for practical applications. To this end, low-bit neural network quantization provides a powerful solution to dramatically reduce their model size. However, current quantization methods are based on uniform precision and fail to account for the varying performance sensitivity at different model components to quantization errors. In this paper, novel mixed precision DNN quantization methods are proposed by applying locally variable bit-widths to individual TCN components of a TF masking based multi-channel speech separation system. The optimal local precision settings are automatically learned using three techniques. The first two approaches utilize quantization sensitivity metrics based on either the mean square error (MSE) loss function curvature, or the KL-divergence measured between full precision and quantized separation models. The third approach is based on mixed precision neural architecture search. Experiments conducted on the LRS3-TED corpus simulated overlapped speech data suggest that the proposed mixed precision quantization techniques consistently outperform the uniform precision baseline speech separation systems of comparable bit-widths in terms of SI-SNR and PESQ scores as well as word error rate (WER) reductions up to 2.88% absolute (8% relative).