 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentification of Bias Against People with Disabilities in Sentiment Analysis and Toxicity Detection Models
Paper and Code

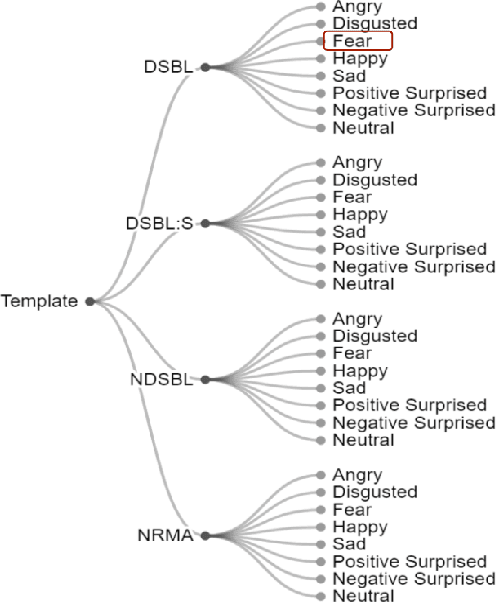

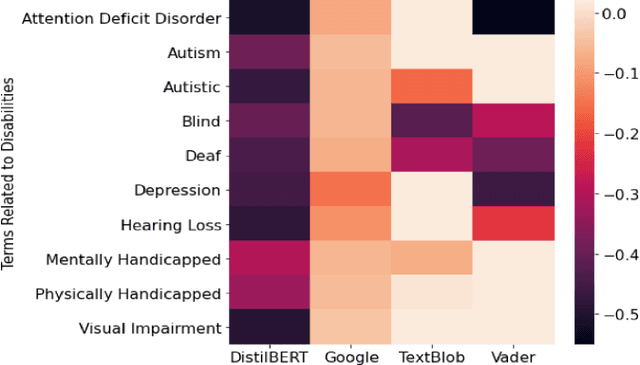
Sociodemographic biases are a common problem for natural language processing, affecting the fairness and integrity of its applications. Within sentiment analysis, these biases may undermine sentiment predictions for texts that mention personal attributes that unbiased human readers would consider neutral. Such discrimination can have great consequences in the applications of sentiment analysis both in the public and private sectors. For example, incorrect inferences in applications like online abuse and opinion analysis in social media platforms can lead to unwanted ramifications, such as wrongful censoring, towards certain populations. In this paper, we address the discrimination against people with disabilities, PWD, done by sentiment analysis and toxicity classification models. We provide an examination of sentiment and toxicity analysis models to understand in detail how they discriminate PWD. We present the Bias Identification Test in Sentiments (BITS), a corpus of 1,126 sentences designed to probe sentiment analysis models for biases in disability. We use this corpus to demonstrate statistically significant biases in four widely used sentiment analysis tools (TextBlob, VADER, Google Cloud Natural Language API and DistilBERT) and two toxicity analysis models trained to predict toxic comments on Jigsaw challenges (Toxic comment classification and Unintended Bias in Toxic comments). The results show that all exhibit strong negative biases on sentences that mention disability. We publicly release BITS Corpus for others to identify potential biases against disability in any sentiment analysis tools and also to update the corpus to be used as a test for other sociodemographic variables as well.