 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Transfer Learning: a simple but effective transfer learning
Paper and Code
Nov 22, 2021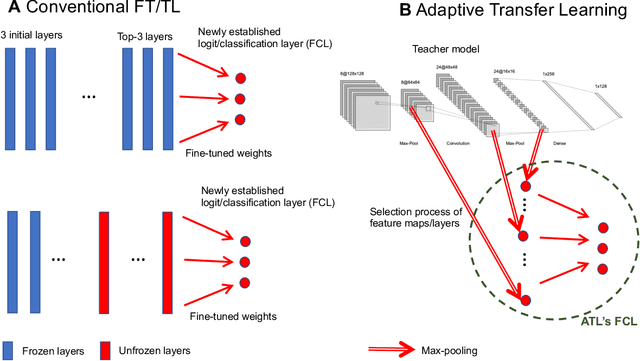
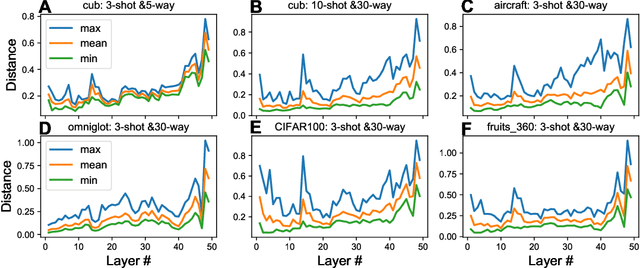
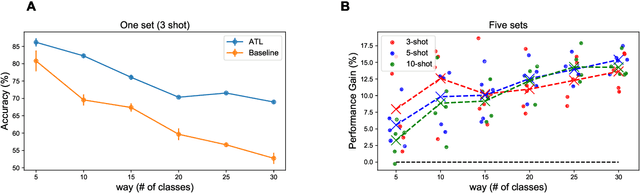
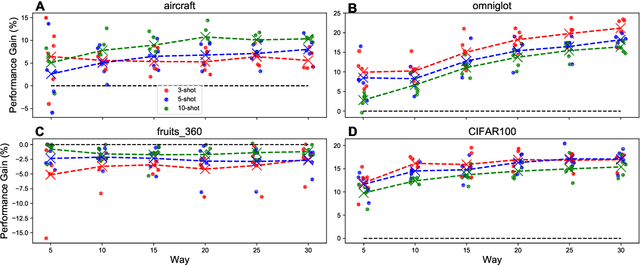
Transfer learning (TL) leverages previously obtained knowledge to learn new tasks efficiently and has been used to train deep learning (DL) models with limited amount of data. When TL is applied to DL, pretrained (teacher) models are fine-tuned to build domain specific (student) models. This fine-tuning relies on the fact that DL model can be decomposed to classifiers and feature extractors, and a line of studies showed that the same feature extractors can be used to train classifiers on multiple tasks. Furthermore, recent studies proposed multiple algorithms that can fine-tune teacher models' feature extractors to train student models more efficiently. We note that regardless of the fine-tuning of feature extractors, the classifiers of student models are trained with final outputs of feature extractors (i.e., the outputs of penultimate layers). However, a recent study suggested that feature maps in ResNets across layers could be functionally equivalent, raising the possibility that feature maps inside the feature extractors can also be used to train student models' classifiers. Inspired by this study, we tested if feature maps in the hidden layers of the teacher models can be used to improve the student models' accuracy (i.e., TL's efficiency). Specifically, we developed 'adaptive transfer learning (ATL)', which can choose an optimal set of feature maps for TL, and tested it in the few-shot learning setting. Our empirical evaluations suggest that ATL can help DL models learn more efficiently, especially when available examples are limited.