 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCritical Sentence Identification in Legal Cases Using Multi-Class Classification
Paper and Code
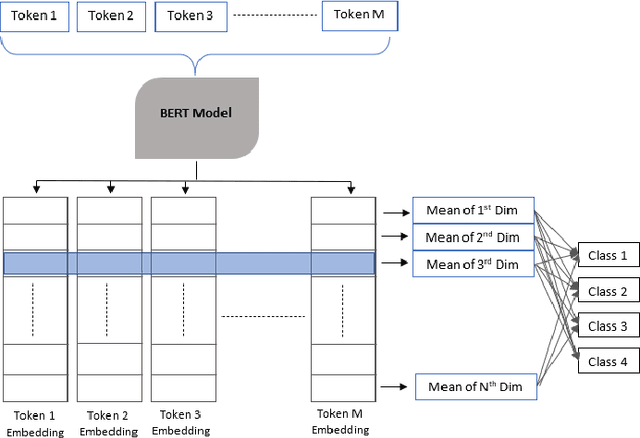
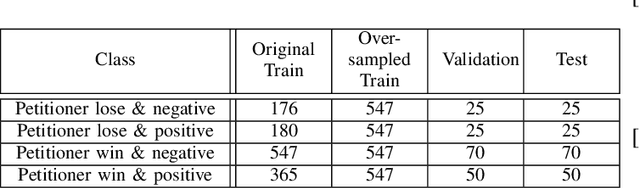
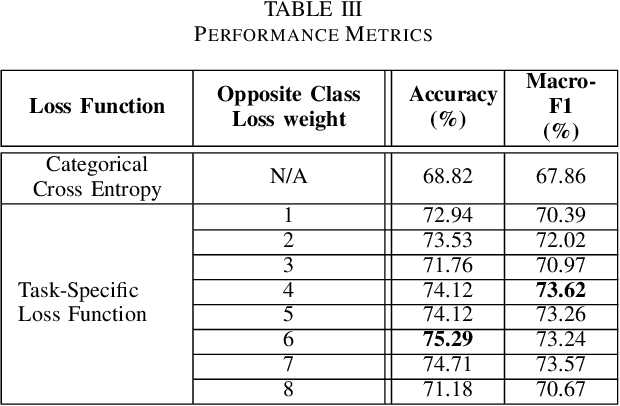
Inherently, the legal domain contains a vast amount of data in text format. Therefore it requires the application of Natural Language Processing (NLP) to cater to the analytically demanding needs of the domain. The advancement of NLP is spreading through various domains, such as the legal domain, in forms of practical applications and academic research. Identifying critical sentences, facts and arguments in a legal case is a tedious task for legal professionals. In this research we explore the usage of sentence embeddings for multi-class classification to identify critical sentences in a legal case, in the perspective of the main parties present in the case. In addition, a task-specific loss function is defined in order to improve the accuracy restricted by the straightforward use of categorical cross entropy loss.