 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Time Irreversibility with Order-Contrastive Pre-training
Paper and Code
Nov 04, 2021
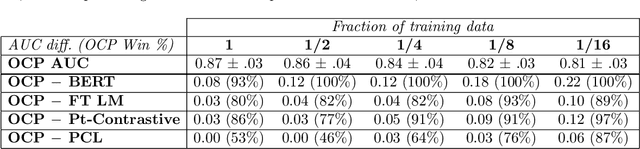
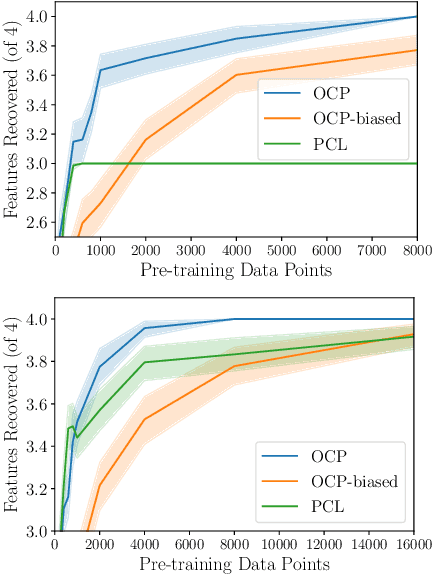

Label-scarce, high-dimensional domains such as healthcare present a challenge for modern machine learning techniques. To overcome the difficulties posed by a lack of labeled data, we explore an "order-contrastive" method for self-supervised pre-training on longitudinal data. We sample pairs of time segments, switch the order for half of them, and train a model to predict whether a given pair is in the correct order. Intuitively, the ordering task allows the model to attend to the least time-reversible features (for example, features that indicate progression of a chronic disease). The same features are often useful for downstream tasks of interest. To quantify this, we study a simple theoretical setting where we prove a finite-sample guarantee for the downstream error of a representation learned with order-contrastive pre-training. Empirically, in synthetic and longitudinal healthcare settings, we demonstrate the effectiveness of order-contrastive pre-training in the small-data regime over supervised learning and other self-supervised pre-training baselines. Our results indicate that pre-training methods designed for particular classes of distributions and downstream tasks can improve the performance of self-supervised learning.