 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of Tree Based Regression over Multiple Linear Regression for Non-normally Distributed Data in Battery Performance
Paper and Code
Nov 03, 2021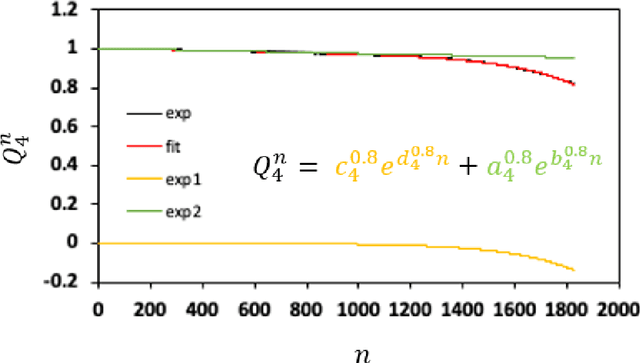
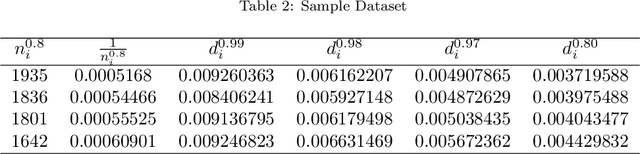
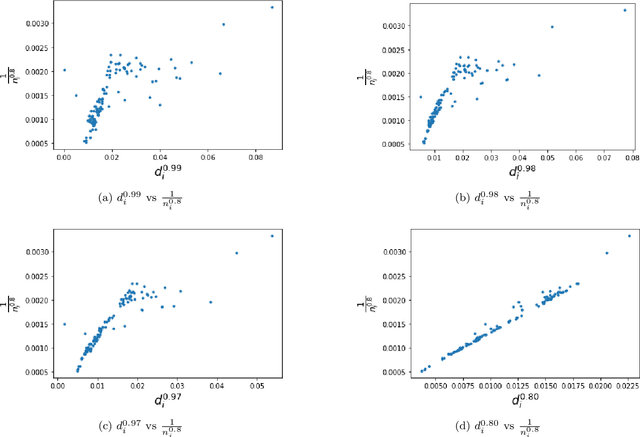
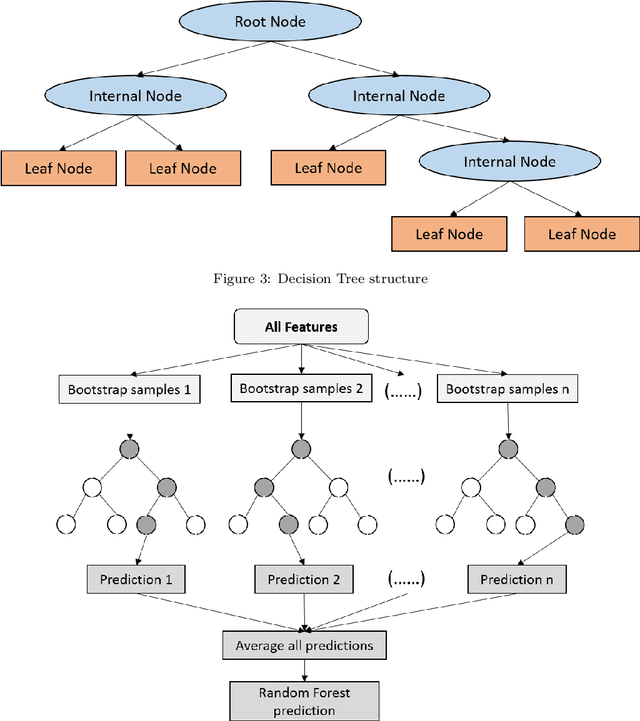
Battery performance datasets are typically non-normal and multicollinear. Extrapolating such datasets for model predictions needs attention to such characteristics. This study explores the impact of data normality in building machine learning models. In this work, tree-based regression models and multiple linear regressions models are each built from a highly skewed non-normal dataset with multicollinearity and compared. Several techniques are necessary, such as data transformation, to achieve a good multiple linear regression model with this dataset; the most useful techniques are discussed. With these techniques, the best multiple linear regression model achieved an R^2 = 81.23% and exhibited no multicollinearity effect for the dataset used in this study. Tree-based models perform better on this dataset, as they are non-parametric, capable of handling complex relationships among variables and not affected by multicollinearity. We show that bagging, in the use of Random Forests, reduces overfitting. Our best tree-based model achieved accuracy of R^2 = 97.73%. This study explains why tree-based regressions promise as a machine learning model for non-normally distributed, multicollinear data.