Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing Evaluation Metrics for Speech-to-Speech Translation
Paper and Code
Oct 26, 2021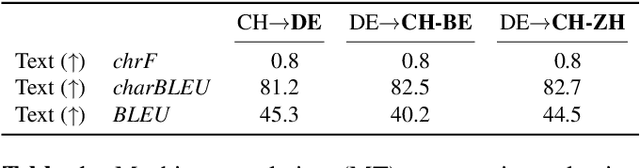
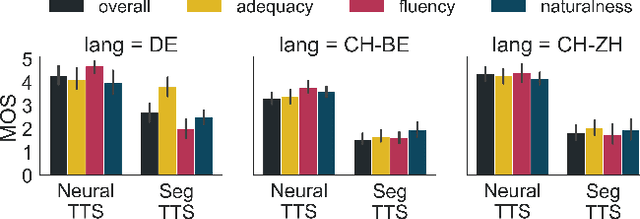
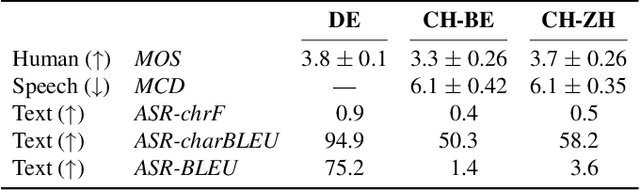
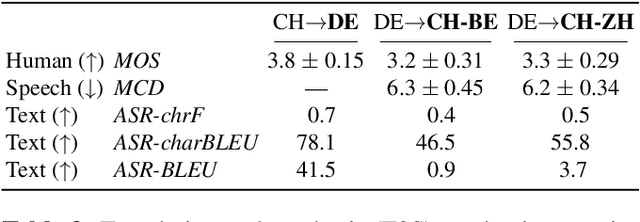
Speech-to-speech translation combines machine translation with speech synthesis, introducing evaluation challenges not present in either task alone. How to automatically evaluate speech-to-speech translation is an open question which has not previously been explored. Translating to speech rather than to text is often motivated by unwritten languages or languages without standardized orthographies. However, we show that the previously used automatic metric for this task is best equipped for standardized high-resource languages only. In this work, we first evaluate current metrics for speech-to-speech translation, and second assess how translation to dialectal variants rather than to standardized languages impacts various evaluation methods.
* ASRU 2021
View paper on